| Новые программы oszone.net |
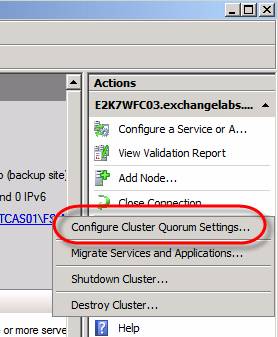
Во второй части этого цикла статей мы рассмотрели стратегии растянутых сайтов Active Directory, а также рекомендуемые значения таймаутов задержки сети и тактовых импульсов. В этой части мы продолжим с того места, на котором остановились во второй части. Мы рассмотрим стратегии транспортной корзины, а также конфигурацию файлового ресурса-свидетеля. Стратегия транспортной корзиныВ случае катастрофы основной центр данных сделает все серверы недоступными, и сообщения будут содержаться в транспортной корзине серверов Hub Transport основного центра данных. Эти сообщения не смогут быть повторно предоставлены серверу CMS после обхода отказа (с потерями) на пассивном узле кластера резервного центра данных. В зависимости от того, сколько логов было потеряно для каждой группы хранения во время обхода отказа, возникнет потеря данных. В результате могут поступить жалобы от конечных пользователей. Однако следует отметить, что существует возможность перемещения очереди серверов HT на серверы HT в резервном центре данных и повторной пересылки содержимого очереди. Здесь важное значение имеют настройки тайминга. Чтобы сообщения, содержащиеся в транспортной корзине, были повторно отправлены, очереди необходимо переместить до того, как кластер выполнит отчистку транспортной корзины. В противном случае сообщения из транспортной корзины будут недоступны в силу отсутствия. Для подробной информации о том, как перемещать очереди сообщений на другой сервер HT перейдите по следующей ссылке. Размещение файлового ресурса-свидетеля (File Share Witness)Кластер на базе CCR использует модель кворума «большинство узлов с файловым ресурсом-свидетелем» (Node majority with File Share Witness (FSW)), что, по сути, означает, что хотя кластер CCR имеет всего два кластерных узла, существует третий узел под названием файловый ресурс-свидетель. Как правило, это сервер HT на том же AD сайте, на котором расположены узлы кластера CCR. В таком типе модели кворума двух узлов недостаточно для поддержки работы в случае отказа одного узла кластера. Чтобы обеспечить работу в случае отказа одного из узлов в кластере на базе модели кворума Node majority with File Share Witness (FSW), должны быть как минимум три устройства, которые можно считать доступными. FSW действует в качестве третьего доступного устройства в кластере кворума Node majority with File Share Witness (FSW) с двумя узлами, а это означает, что такой тип кластера способен обеспечивать работу в случае отказа на одном узле кластера. К тому же, FSW защищает кластер от синдрома «раздвоения мозга (‘split brain’) и проблемы, известной как ‘partition in time’ (раздел по времени). По сути, это означает, что FSW должен быть доступен, когда возникает отказ на пассивном узле резервного центра данных, в противном случае вы не сможете вывести сервер CMS в режим онлайн, пока не создадите новый FSW на сервере HT в резервном центре данных, а также настроите кластер Windows Failover так, чтобы он указывал на этот сервер HT. Это значительно осложняет процесс обхода отказа. По возможности, другим решением будет размещение FSW на третьем центре данных. Это не означает, что нужно устанавливать еще один сервер Exchange 2007 HT в третьем центре данных. Использование сервера Hub Transport в качестве FSW является рекомендацией к лучшей методике, когда вы устанавливаете оба узла CCR в одном центре данных. Например, при желании вы можете использовать файловый сервер, который расположен в третьем центре данных. Вы, возможно, слышали, что использование записи CNAME для указания на FSW является хорошей идеей, поскольку это значительно упрощает процесс указания CCR кластера на другой FSW. Нужно лишь заранее создать папку ресурса FSW с соответствующими разрешениями, а затем обновить запись CNAME после сбоя, который поразил основной центр данных. Но даже несмотря на то, что Microsoft поддерживала такой способ, руководство было изменено (более подробно смотрите здесь). Сегодня рекомендуемым способом предварительной инициализации ресурса FSW на другом сервере является использование возможностей встроенной службы кластера «принудительный кворум» (‘force quorum’). Итак, когда ресурс FSW расположен в основном центре данных и катастрофа выводит из строя все серверы в нем, обход отказа на пассивный узел в резервном центре данных не произойдет автоматически. Дело обстоит так, потому что должны быть доступны два голоса, когда обход отказа происходит в кластере на базе MNS. Чтобы вывести ресурсы кластера пассивного узла в режим онлайн, сначала нужно создать новый ресурс FSW на сервере HT (если вы еще его не создали) в резервном центре данных и следовать этим инструкциям , после чего нужно открыть интерпретатор команд на узле кластера в резервном центре данных и ввести: NET START CLUSSVC /forcequorum Это в принудительном порядке запустить службу кластера на этом узле. Теперь откройте консоль Failover Cluster и выберите имя кластера в левой панели. Затем нажмите Дополнительные действия (More Actions) в панели действий и опцию Настроить параметры кворума кластера (Configure Cluster Quorum Settings) в контекстном меню, как показано на рисунке 1. Примечание: в Windows 2003 ключ /forcequorum был ключом режима обслуживания. По сути, мы приказывали ОС Windows запустить службу кластера. С Windows Server 2008 дело обстоит не так. При использовании ключа /forcequorum в Windows Server 2008 Failover Clusters вы говорите кластеру, что конфигурация на этом узле сейчас настроена в качестве мастера. Это в свою очередь означает, что, когда другой узел кластера возвращается в рабочий режим и объединяется с кластером, он замещает информацию конфигурации на исходную на этом узле. Это очень важное изменение!
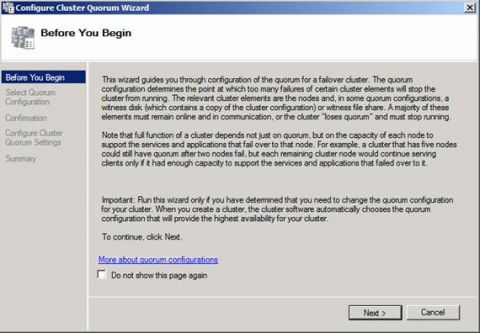
Рисунок 1: Выбор параметров настройки кворума кластера Жмем Далее.
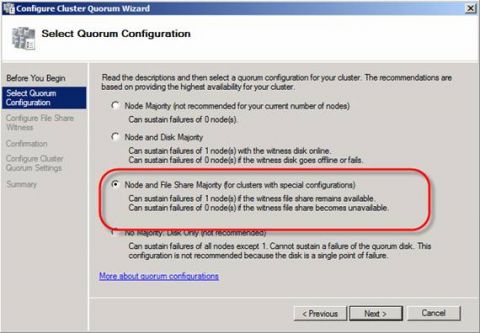
Рисунок 2: Приветственная страница мастера настройки кворума кластера Выберите опцию Node and File Share Majority (for clusters with special configurations), как показано на рисунке 3 и нажмите Далее.
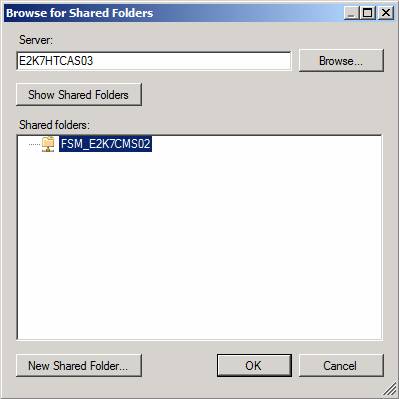
Рисунок 3: Выбор правильной модели кворума Нажмите кнопку Обзор и введите имя сервера HT, на котором вы создали FSW ресурс. Нажмите Показать общие папки (Show Shared Folders) (рисунок 4) и выберите FSW ресурс. Нажмите OK.
Рисунок 4: Выбор нового ресурса FSW Дважды нажмите Далее, а затем Закончить. Рисунок 5: Ресурсы кластера в режиме онлайн на узле кластера в резервном центре данных Когда основной центр данных снова работает, создайте новый ресурс FSW на старом сервере HT. Затем следуйте вышеописанным шагам для настройки указания кластера на этот ресурс FSW. Когда все необходимые серверы снова в интерактивном режиме на основном центре данных, вы можете переместить сервер CMS обратно на узел кластера в основном центре данных. Примечание:С момента выхода Exchange 2007 RTM я получил множество вопросов относительно FSW. Один из них был связан с возможностью/невозможностью использования FSW в сочетании с DFS, чтобы можно было использовать несколько серверов в качестве FSW. Хотя это довольно интересная мысль, такая конфигурация не поддерживается.
Теги:
Exchange 2007, CCR-кластеры.
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|