| Новые программы oszone.net |
CheckBootSpeed - это диагностический пакет на основе скриптов PowerShell, создающий отчет о скорости загрузки Windows 7 ...
Вы когда-нибудь хотели создать установочный диск Windows, который бы автоматически установил систему, не задавая вопросо...
Если после установки Windows XP у вас перестала загружаться Windows Vista или Windows 7, вам необходимо восстановить заг...
Программа подготовки документов и ведения учетных и отчетных данных по командировкам. Используются формы, утвержденные п...
Red Button – это мощная утилита для оптимизации и очистки всех актуальных клиентских версий операционной системы Windows...
Нашу курсовую мы разделим на 4 части
- общий обзор
- более специфическое исследование сетевой активности
- пройдемся через вызовы функций
- разберём основные структуры данных и участки кода
Рассмотрим подробнее что происходит с пакетом при попадании в нашу
машину. Сначала он обрабатывается драйвером аппаратуры(сетевой карты и
т.д) если пакет предназначен нам то он посылается на выше лежаций
уровень - сетевой там определяется для кого он предназначен: нам или
кому-то другому, для етого просматривается кэш маршрутизации,если там
нет маршрута то Forwarding Information Base (FIB), если пакет
предназначен другому компьютеру то ядро шлёт его на соответствующее
устройство (сетевую карту) ,если нам ,то через транспортный и
вышележашие уровни приложению. Обмен данными между приложением и ядром
осуществляется через абстракцию сокета.В Линухе используется BSD
сокеты.
Рассмотрим поподробнее структуру пакета
Ключ к быстрому обмену данными в использовании структуры sk_buf и
передачи на вышестоящии уровни тобько указаттеля на неё
описание структуры лежит в linux/skbuff.h
её поля
struct sk_buff {
/* These two members must be first. */
struct sk_buff * next; /* Next buffer in list */
struct sk_buff * prev; /* Previous buffer in list */
struct sk_buff_head * list; /* List we are on */
struct sock *sk; /* Socket we are owned by */
struct timeval stamp; /* Time we arrived */
struct net_device *dev; /* Device we arrived on/are leaving by */
/* Transport layer header */
union
{
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct spxhdr *spxh;
unsigned char *raw;
} h;
/* Network layer header */
union
{
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
struct ipxhdr *ipxh;
unsigned char *raw;
} nh;
/* Link layer header */
union
{
struct ethhdr *ethernet;
unsigned char *raw;
} mac;
struct dst_entry *dst;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48];
unsigned int len; /* Length of actual data */
unsigned int data_len;
unsigned int csum; /* Checksum */
unsigned char __unused, /* Dead field, may be reused */
cloned, /* head may be cloned (check refcnt to be sure). */
pkt_type, /* Packet class */
ip_summed; /* Driver fed us an IP checksum */
__u32 priority; /* Packet queueing priority */
atomic_t users; /* User count - see datagram.c,tcp.c */
unsigned short protocol; /* Packet protocol from driver. */
unsigned short security; /* Security level of packet */
unsigned int truesize; /* Buffer size */
unsigned char *head; /* Head of buffer */
unsigned char *data; /* Data head pointer */
unsigned char *tail; /* Tail pointer */
unsigned char *end; /* End pointer */
void (*destructor)(struct sk_buff *); /* Destruct function */
#ifdef CONFIG_NETFILTER
/* Can be used for communication between hooks. */
unsigned long nfmark;
/* Cache info */
__u32 nfcache;
/* Associated connection, if any */
struct nf_ct_info *nfct;
#ifdef CONFIG_NETFILTER_DEBUG
unsigned int nf_debug;
#endif
#endif /*CONFIG_NETFILTER*/
#if defined(CONFIG_HIPPI)
union{
__u32 ifield;
} private;
#endif
#ifdef CONFIG_NET_SCHED
__u32 tc_index; /* traffic control index */
#endif
};
там же содержится масса полезных функций для работы с sk_buff. все
протоколы используют ету структуру добавляя заголовки своего уровня
Маршрутизация
Уровень IP использует 3 структуры для маршрутизации FIB где хранятся
все маршруты routing cache где находятся наиболее часто используемые
neibour table список компьютеров физически соединенных с данным
FIB содержит 32 зоны по одной на каждый бит ip адреса каждая зона
содержит точки входа для хостов и сетей которые задайтся данной маской
подсети 255.0.0.0 имеет 8 значащих бит и поэтому в восьмой зоне
255.255.255.0 в 24 зоне
файл /proc/net/route содержит FIB
routing cache хэш-таблица которая содержит до 256 цепочек меаршрутов
если подходящий маршрут не найден в кэше то он добавляется туда из FIB
устаревшие записи по истечении некоторого времени удаляются содержимое
кэша можно увидеть в /proc/net/rt_cache
Инициализация сети
главные настройки сети в дистрибутиве RedHat (Mandrake) лежат в
/etc/sysconfig/network ,/etc/sysconfig/network-scripts/ifcfg-eth0 и
тд...
содержимое моих файлов (не в virtual mashine редхате а на нормальной
машине Mandrake-8.2 где соответственно нет никаких сетевых карт)
/etc/sysconfig/network
NETWORKING=yes
FORWARD_IPV4=false
HOSTNAME=freeland.linux
DOMAINNAME=linux
/etc/sysconfig/network-scripts/ifcfg-lo
DEVICE=lo
IPADDR=127.0.0.1
NETMASK=255.0.0.0
NETWORK=127.0.0.0
# If you`re having problems with gated making 127.0.0.0/8 a martian,
# you can change this to something else (255.255.255.255, for example)
BROADCAST=127.255.255.255
ONBOOT=yes
NAME=loopback
Очень полезной программой являеся ifconfig синтаксис которой подробно
рассмотрен в мануале
[20:16][pts1]/etc/sysconfig/network-scripts [root]
#ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:3242 errors:0 dropped:0 overruns:0 frame:0
TX packets:3242 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:227644 (222.3 Kb) TX bytes:227644 (222.3 Kb)
не менее полезна команда route
#route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
127.0.0.0 * 255.0.0.0 U 0 0 0 lo
её назначение ,а также многих других описано в Linux Network
Administrator Guide
Соединения
В этой части мы подробно рассмотрим сокеты и всё что с ними связано
Когда процесс создаёт сокет то он пустой потом система определяет
маршрут к удалённому хосту и вносит ету информацию в сокет.После этого
пакеты направляются на нужное устройство
Есть два типа сокетов BSD сокеты которые включают как член INET cокеты
BSD сокеты описываются структурой struct socket в linux/net.h
struct socket
{
socket_state state;
unsigned long flags;
struct proto_ops *ops;
struct inode *inode;
struct fasync_struct *fasync_list; /* Asynchronous wake up list */
struct file *file; /* File back pointer for gc */
struct sock *sk;
wait_queue_head_t wait;
short type;
unsigned char passcred;
};
struct proto_ops {
int family;
int (*release) (struct socket *sock);
int (*bind) (struct socket *sock, struct sockaddr *umyaddr,
int sockaddr_len);
int (*connect) (struct socket *sock, struct sockaddr *uservaddr,
int sockaddr_len, int flags);
int (*socketpair) (struct socket *sock1, struct socket *sock2);
int (*accept) (struct socket *sock, struct socket *newsock,
int flags);
int (*getname) (struct socket *sock, struct sockaddr *uaddr,
int *usockaddr_len, int peer);
unsigned int (*poll) (struct file *file, struct socket *sock, struct poll_tabl
e_struct *wait);
int (*ioctl) (struct socket *sock, unsigned int cmd,
unsigned long arg);
int (*listen) (struct socket *sock, int len);
int (*shutdown) (struct socket *sock, int flags);
int (*setsockopt) (struct socket *sock, int level, int optname,
char *optval, int optlen);
int (*getsockopt) (struct socket *sock, int level, int optname,
char *optval, int *optlen);
int (*sendmsg) (struct socket *sock, struct msghdr *m, int total_len, struct s
cm_cookie *scm);
int (*recvmsg) (struct socket *sock, struct msghdr *m, int total_len, int flag
s, struct scm_cookie *scm);
int (*mmap) (struct file *file, struct socket *sock, struct vm_area_struct * v
ma);
ssize_t (*sendpage) (struct socket *sock, struct page *page, int offset, size_
t size, int flags);
};
наиболее важные поля
* struct proto_ops *ops указывает на протокольно зависимые функции
struct inode на inode файла сокета
struct sock* на инет сокет
INET net/sock.h struct sock
struct sock {
/* Socket demultiplex comparisons on incoming packets. */
__u32 daddr; /* Foreign IPv4 addr */
__u32 rcv_saddr; /* Bound local IPv4 addr */
__u16 dport; /* Destination port */
unsigned short num; /* Local port */
int bound_dev_if; /* Bound device index if != 0 */
/* Main hash linkage for various protocol lookup tables. */
struct sock *next;
struct sock **pprev;
struct sock *bind_next;
struct sock **bind_pprev;
volatile unsigned char state, /* Connection state */
zapped; /* In ax25 & ipx means not linked */
__u16 sport; /* Source port */
unsigned short family; /* Address family */
unsigned char reuse; /* SO_REUSEADDR setting */
unsigned char shutdown;
atomic_t refcnt; /* Reference count */
socket_lock_t lock; /* Synchronizer... */
int rcvbuf; /* Size of receive buffer in bytes */
wait_queue_head_t *sleep; /* Sock wait queue */
struct dst_entry *dst_cache; /* Destination cache */
rwlock_t dst_lock;
atomic_t rmem_alloc; /* Receive queue bytes committed */
struct sk_buff_head receive_queue; /* Incoming packets */
atomic_t wmem_alloc; /* Transmit queue bytes committed */
struct sk_buff_head write_queue; /* Packet sending queue */
atomic_t omem_alloc; /* "o" is "option" or "other" */
int wmem_queued; /* Persistent queue size */
int forward_alloc; /* Space allocated forward. */
__u32 saddr; /* Sending source */
unsigned int allocation; /* Allocation mode */
int sndbuf; /* Size of send buffer in bytes */
struct sock *prev;
/* Not all are volatile, but some are, so we might as well say they all are.
* XXX Make this a flag word -DaveM
*/
volatile char dead,
done,
urginline,
keepopen,
linger,
destroy,
no_check,
broadcast,
bsdism;
unsigned char debug;
unsigned char rcvtstamp;
unsigned char use_write_queue;
unsigned char userlocks;
/* Hole of 3 bytes. Try to pack. */
int route_caps;
int proc;
unsigned long lingertime;
int hashent;
struct sock *pair;
/* The backlog queue is special, it is always used with
* the per-socket spinlock held and requires low latency
* access. Therefore we special case it`s implementation.
*/
struct {
struct sk_buff *head;
struct sk_buff *tail;
} backlog;
rwlock_t callback_lock;
/* Error queue, rarely used. */
struct sk_buff_head error_queue;
struct proto *prot;
#if defined(CONFIG_IPV6) || defined (CONFIG_IPV6_MODULE)
union {
struct ipv6_pinfo af_inet6;
} net_pinfo;
#endif
union {
struct tcp_opt af_tcp;
#if defined(CONFIG_INET) || defined (CONFIG_INET_MODULE)
struct raw_opt tp_raw4;
#endif
#if defined(CONFIG_IPV6) || defined (CONFIG_IPV6_MODULE)
struct raw6_opt tp_raw;
#endif /* CONFIG_IPV6 */
#if defined(CONFIG_SPX) || defined (CONFIG_SPX_MODULE)
struct spx_opt af_spx;
#endif /* CONFIG_SPX */
} tp_pinfo;
int err, err_soft; /* Soft holds errors that don`t
cause failure but are the cause
of a persistent failure not just
`timed out` */
unsigned short ack_backlog;
unsigned short max_ack_backlog;
__u32 priority;
unsigned short type;
unsigned char localroute; /* Route locally only */
unsigned char protocol;
struct ucred peercred;
int rcvlowat;
long rcvtimeo;
long sndtimeo;
#ifdef CONFIG_FILTER
/* Socket Filtering Instructions */
struct sk_filter *filter;
#endif /* CONFIG_FILTER */
/* This is where all the private (optional) areas that don`t
* overlap will eventually live.
*/
union {
void *destruct_hook;
struct unix_opt af_unix;
#if defined(CONFIG_INET) || defined (CONFIG_INET_MODULE)
struct inet_opt af_inet;
#endif
#if defined(CONFIG_ATALK) || defined(CONFIG_ATALK_MODULE)
struct atalk_sock af_at;
#endif
#if defined(CONFIG_IPX) || defined(CONFIG_IPX_MODULE)
struct ipx_opt af_ipx;
#endif
#if defined (CONFIG_DECNET) || defined(CONFIG_DECNET_MODULE)
struct dn_scp dn;
#endif
#if defined (CONFIG_PACKET) || defined(CONFIG_PACKET_MODULE)
struct packet_opt *af_packet;
#endif
#if defined(CONFIG_X25) || defined(CONFIG_X25_MODULE)
x25_cb *x25;
#endif
#if defined(CONFIG_AX25) || defined(CONFIG_AX25_MODULE)
ax25_cb *ax25;
#endif
#if defined(CONFIG_NETROM) || defined(CONFIG_NETROM_MODULE)
nr_cb *nr;
#endif
#if defined(CONFIG_ROSE) || defined(CONFIG_ROSE_MODULE)
rose_cb *rose;
#endif
#if defined(CONFIG_PPPOE) || defined(CONFIG_PPPOE_MODULE)
struct pppox_opt *pppox;
#endif
#ifdef CONFIG_NETLINK
struct netlink_opt *af_netlink;
#endif
#if defined(CONFIG_ECONET) || defined(CONFIG_ECONET_MODULE)
struct econet_opt *af_econet;
#endif
#if defined(CONFIG_ATM) || defined(CONFIG_ATM_MODULE)
struct atm_vcc *af_atm;
#endif
#if defined(CONFIG_IRDA) || defined(CONFIG_IRDA_MODULE)
struct irda_sock *irda;
#endif
#if defined(CONFIG_WAN_ROUTER) || defined(CONFIG_WAN_ROUTER_MODULE)
struct wanpipe_opt *af_wanpipe;
#endif
} protinfo;
/* This part is used for the timeout functions. */
struct timer_list timer; /* This is the sock cleanup timer. */
struct timeval stamp;
/* Identd and reporting IO signals */
struct socket *socket;
/* RPC and TUX layer private data */
void *user_data;
/* Callbacks */
void (*state_change)(struct sock *sk);
void (*data_ready)(struct sock *sk,int bytes);
void (*write_space)(struct sock *sk);
void (*error_report)(struct sock *sk);
int (*backlog_rcv) (struct sock *sk,
struct sk_buff *skb);
void (*destruct)(struct sock *sk);
};
Эта структура очень широко используется и имеет много hacks зависящих
от конфигурации как видим для каждого протокола здесь найдется
местечко
Сокеты проходят через процесс маршрутизации только один раз для
каждого маршрута.Они содержат указатель на маршрут struct sock-
>dst_cache* и вызывают ip_route_connect (net/route.h) для нахождения
маршрута информация записывается в dst_cache и сокет дальше использует
её не повторяя операции поиска маршрута пока не случится что-то
необычное в етом и есть смысл connect
Установление соединеиния
Рассмотрим стандартный пример
/* look up host */
server = gethostbyname(SERVER_NAME);
/* get socket */
sockfd = socket(AF_INET, SOCK_STREAM, 0);
/* set up address */
address.sin_family = AF_INET;
address.sin_port = htons(PORT_NUM);
memcpy(&address.sin_addr,server->h_addr,server->h_length);
/* connect to server */
connect(sockfd, &address, sizeof(address));
socket создаёт обект сокета определенного типа и инициалищирует его
также делает дефолтовские очереди (incoming,outgoing,error,backlog) и
заголовок TCP
connect определяет маршруты вызывая протокольно зависимые функции
(tcp_v4_connect(),udp_connect()) net/socket.c
asmlinkage long sys_connect(int fd, struct sockaddr *uservaddr, int addrlen)
{
................................
err = sock->ops->connect(sock, (struct sockaddr *) address, addrlen,
sock->file->f_flags);
..........................
}
int sock_create(int family, int type, int protocol, struct socket **res)
{
.....................................
//cоздаем протокольно зависимый сокет!
//--------------------------------------
if ((i = net_families[family]->create(sock, protocol)) < 0)
{
sock_release(sock);
goto out;
}
.................
}
Функции
Socket
Проверяем ошибки
Выделяем память
Ложим сокет в список inode
Устанавливаем указатели на протокольно зависмые части
Сохраняем данные про тип и параметры сокета
Устанавливаем сокет в положение закрыт
Инициализируем очереди пакетов
Connect
Проверяем ошибки
Определяем Маршрут
Проверяем кэш
Смотрим в FIB
Создаем новую запись в таблице маршрутизации
Заполняем её и вощвращаем
Сохраняем указатель на запись маршрутишации в сокете
Вызываем протокольно зависимую функцию connect
Устанавливаем сокет в соединенный
Также надо не забыть закрыть сокет
Close вызывает sock_close in socket.c
void sock_release(struct socket *sock)
{
if (sock->ops)
sock->ops->release(sock);
...........................
}
а та через цепочку вызовов протокольнозависимую функцию
Дополнительные функции
void inet_sock_release(struct sock *sk) -net/ipv4/af_inet.c
назвние говорит за себя + хороший комментарий Алана Коха
fib_lookup() - include/net/ip_fib.h
возвращает маршрут .Написана русским -Кузнецов!
fn_hach_lookup net/fib_hash.c
возвращает маршрут по адресу
inet_create net/ipv4/af_inet.c
создает сокет
inet_release <||>
ip_route_connect
вызывает ip_route_output для определени адреса назначения
ip_route_output
ip_route_output_slow
rt_intern_hash полезные для маршрутизации функции
sock_close()
sock_create()
sock_init_data net/core/sock.c инициализирует основные поля сокета
sock_release net/socket.c
sys_socket
tcp_close net/ipv4/tcp.c
устанавливает флаг FYN
tpc_connect net/ipv4/tpc_output.c
сохдает пакеты для соединения с установленым размером окна
и соответствующими битами,ложит пакет в очередь и выpывает
tcp_transmit_skb чтоб послать пакет
tcp_transmit_skb -заполняет заголовок пакета и передает его
на уроветь IP
tcp_v4_connect()
вызывает ip_route_connect
создает соединительный пакет и вызывает tcp_connect
udp_close
udp_connect
Обмен данными
Эта часть описывает процесс обмена данными между различными уровнями
ядра и сети Когда приложение отправляет данные то оно пишет в сокет
тот в своб оуередь определяет свой тип и вызывает соответствующую
функцию,та передает данные протоколу транспортного уровня(tcp,udp)
функции етого уровня создают структуру sk_buff,копируют в неё данные
заполняют заголовок своего уровня,считают контрольную сумму и шлют на
уровень IP.Там дописывается заголовок ip,checksum,возможно пакет фраг
менторуется и шлётся на xmit очередь сетевого девайса ,тот посылает
пакет в сеть.
dev_queue_xmit() - net/core/dev.c
spin_lock_bh() -блокируем девайс
если у него есть очередь
calls enqueue() добавляем пакет
calls qdis() пробуждаем девайс
else calls dev->hard_start_xmit()
calls spin_unlock_bh() освобождаем девайс
DEVICE->hard_start_xmit() - зависит от девайса, drivers/net/DEVICE.c
в общем проверяет открыто ли устройство
посылает заголовок
говорит системной шине послать пакет
обновляет статус
inet_sendmsg() - net/ipv4/af_inet.c
int inet_sendmsg(struct socket *sock, struct msghdr *msg, int size,
struct scm_cookie *scm)
{
struct sock *sk = sock->sk;
/*биндим сокет. */
if (sk->num==0 && inet_autobind(sk) != 0)
return -EAGAIN;
вызываем функцию протокола чтоб послать данные
return sk->prot->sendmsg(sk, msg, size);
}
ip_build_xmit - net/ipv4/ip_output.c (604)
calls sock_alloc_send_skb() выделяем память
=заголовочек=
if(!sk->protinfo.af_inet.hdrincl) {
iph->version=4;
iph->ihl=5;
iph->tos=sk->protinfo.af_inet.tos;
iph->tot_len = htons(length);
iph->frag_off = df;
iph->ttl=sk->protinfo.af_inet.mc_ttl;
ip_select_ident(iph, &rt->u.dst, sk);
if (rt->rt_type != RTN_MULTICAST)
iph->ttl=sk->protinfo.af_inet.ttl;
iph->protocol=sk->protocol;
iph->saddr=rt->rt_src;
iph->daddr=rt->rt_dst;
iph->check=0;
iph->check = ip_fast_csum((unsigned char *)iph, iph->ihl);
err = getfrag(frag, ((char *)iph)+iph->ihl*4,0, length-iph->ihl*4);
}
calls getfrag() копируем данные у юзера
returns rt->u.dst.output() [= dev_queue_xmit()]
ip_queue_xmit() - net/ipv4/ip_output.c (234)
cмотри маршрут
достраиваем ip заголовок
фрагментирум если надо
adds IP checksum
calls skb->dst->output() [= dev_queue_xmit()]
qdisc_restart() - net/sched/sch_generic.c (50)
вырываем пакет из очереди
calls dev->hard_start_xmit()
обновляем статистику
if если ошибка опять стввим пакет в очередь
sock_sendmsg() - net/socket.c (325)
проверяем права и всё такое
calls scm_sendmsg() [socket control message]
шлёмс данные
calls sock->ops[inet]->sendmsg() and destroys scm
>>> sock_write() - net/socket.c (399)
calls socki_lookup() accоциируем сокет с inode
заполняем заголовок сообщения
returns sock_sendmsg()
tcp_sendmsg() - net/ipv4/tcp.c (755)
ждемс соединения
skb = tcp_alloc_pskb память
calls csum_and_copy_from_user() делаем checksum & копируем
calls tcp_send_skb()
tcp_send_skb() - net/ipv4/tcp_output.c (160)
это главная routine посылки буфера
мы ставим буфер в очередь и решаем оставить его там или послать
calls __skb_queue_tail() добавляем в очередь
calls tcp_transmit_skb() если может
tcp_transmit_skb() - net/ipv4/tcp_output.c (77)
строим заголовок tcp и чексумму
calls tcp_build_and_update_options()
проверяем ACKs,SYN
calls tp->af_specific[ip]->queue_xmit()
udp_getfrag() - net/ipv4/udp.c
копируем из адресного пространства пользователя и добавляем checksum
udp_sendmsg() - net/ipv4/udp.c
проверяем флаги и тд
заполняем заголовок
проверяем мультикаст
заполняем маршутную информацию
calls ip_build_xmit()
обновляем статистику udp
returns err
Получение данных
Получение данных начинается с прерывания от сетевой карты.Драйвер
девайса выделяет память и пересылает данные в то пространство.Потом
передает пакет в связующий уровень который вызывает
bottom-halv,которое обрабатывает событие вне прерывания пересылая
данные на уровень выше -ip.Тот проверяет ошибки
фрагменты,маршрутизирует пакет или отсылает на уровень выше(tcp ||
udp) Этот уровень снова проверяет ошибки определяет сокет которому
предназначен пакет и ложит его в очередь сокета.Тот в свою очередь
будит пользовательский процесс и копирует данные в его буфер.
Чтение из сокета(1)
Пытаемся чтото прочитать(и засыпаем)
Заполняем заголовок собщения указателем на буфер(сокет)
проверяем простые ошибки
передаем сообшение inet сокету
Получение пакета
Пробуждение устройства(прерывание)
проверка девайса
Получение заголовка
выделение памяти
ложим пакет в то место судя по всему используя DMA
ставим пакет в очередь
выставляем флаг запуска bottom-halv
BottomHalv
Запуск сетевого боттом-халва
Пересылка пакетов из девайса чтоб не было прерываний
пересылка пакетов на уровень ip
очистка очереди отсылки
возврат
Уровень IP
Проверка ошибок
Дефрагментация если необходимо
Определение маршрута(форвардить или нет)
Отсылка пакета по назначению(TCP||UDP||forwarding)
Получение пакета в UDP
Проверка ошибок
проверка сокета назначения
пересылка пакета в очередь сокета
пробуждения ждущего процесса
Получение TCP
Проверка флагов и ошибок а также не был ли получен пакет ранее
Определение сокета
пересылка пакета в очередь сокета
пробуждения ждущего процесса
Чтение из сокета(2)
Пробуждение процесса
Вызов соответствуюшей функции доставки(udp ||tcp) в буфер пользователя
Возврат
IP forwarding
Рассмотрим подробнее процесс форвардинга пакетов
Сначада идет проверка TTL и уменьшение его на 1 Проверка пакета на
наличие действительного маршрута если такого нет то отсылается
соответствующее icmp cообщение копирование пакета в новый буфер и
освобождение старого Установка нужных ip опций фрагменторование если
необходимо отправка пакета на нужный девайс
DEVICE_rx() девайсно зависимая функция,
пример drivers/net/de600.c
здесь я попытаюсь перевести замечательные комментарии автора
Linux driver for the D-Link DE-600 Ethernet pocket adapter.
*
* Portions (C) Copyright 1993, 1994 by Bjorn Ekwall
* The Author may be reached as bj0rn@blox.se
/*
* Если у нас хороший пакет то забираем его из адаптера
*/
static void
de600_rx_intr(struct net_device *dev)
{
struct sk_buff *skb;
unsigned long flags;
int i;
int read_from;
int size;
register unsigned char *buffer;
save_flags(flags);
cli();
/* Определяем размер пакета */
size = de600_read_byte(RX_LEN, dev); /* нижния байт */
size += (de600_read_byte(RX_LEN, dev) << 8); /* верхний байт */
size -= 4; /* Ignore trailing 4 CRC-bytes */
/* Сообщаем адаптеру куда ложить следующий пакет и получаем */
read_from = rx_page_adr();
next_rx_page();
de600_put_command(RX_ENABLE);
restore_flags(flags);
if ((size < 32) || (size > 1535)) {
printk("%s: Bogus packet size %d.\n", dev->name, size);
if (size > 10000)
adapter_init(dev);
return;
}
skb = dev_alloc_skb(size+2);
if (skb == NULL) {
printk("%s: Couldn`t allocate a sk_buff of size %d.\n",
dev->name, size);
return;
}
/* Иначе*/
skb->dev = dev;
skb_reserve(skb,2); /* Align */
/* `skb->data` указывет на начало буфера данных. */
buffer = skb_put(skb,size);
/* копируем пакет в буфер */
de600_setup_address(read_from, RW_ADDR);
for (i = size; i > 0; --i, ++buffer)
*buffer = de600_read_byte(READ_DATA, dev);
/* Определяем тип протоколa
skb->protocol=eth_type_trans(skb,dev);
/*Передаем на верхний уровень см net/core/dev.c
netif_rx(skb);
/* обновляем статистику */
dev->last_rx = jiffies;
((struct net_device_stats *)(dev->priv))->rx_packets++; /* количество получени
й */
((struct net_device_stats *)(dev->priv))->rx_bytes += size; /* количество полу
ченных байт */
/*
* Если случится что-то плохое во время доставки, netif_rx()
* сделало a mark_bh(INET_BH) для нас и будет работать
* когда мы войдем в bottom-halv.
*/
}
ip_finish_output() net/ipv4/ip_output
определяет девайс для данного маршрута
вызывает функцию девайса[=dev_queue_xmit]
ip_forward -net/ipv4/ip_forward
в этом файле хорошие комментарии
проверяем роутер
если пакет никому не предназначен то дропаем
если плохой TTL аналогично
если неможет пакет отфорвардится то отправляем icmp пакет ICMP_DEST_UNREACH
если необходимо шлем пакет ICMP HOST REDIRECT
копирум и уничтожаем старый пакет
уменьшаем TTL
если необходимо устанавливаем нужные опции ip_forward_options в
ip_forward_finish
ip_rcv net/ipv4/ip_input.c главная функция плучения ip пакета
проверяем ошибки
плохая длина
версия
чексумма
вызываем pskb_trim
вызываем ip_route_input
Процесс маршрутизации
Как уже говорилось есть тоюлица соседей,FIB,routing cache Таблица
соседей содержит адреса(mac) компьютеров которые фищически соединены с
нами.Linux использует АRP для определения адресов ета таблица
динамическая хотя администраторы могут задать статические записи.
Стуктуры связанные с етой таблицей описаны в include/net/neighbour.h
основные структуры. struct neigh_table -их целый связаный список
struct neigh_parms -список содержит разнообразную статистику struct
neighbour -hash таблица соседей ассоциированых с данной таблицей
struct pneig_entry -hash всех девайсов
поля struct neighbour
struct net_device -девайс
hh_cache -указатель на аппаратный кэш
sk_buff_head arp_queuq -очередь arp пакетов
есть local -в ней находятся свои интерфейсы
и main в ней наверное всё остальное
Forwarding Information Database
struct fib_table в include/net/ip_fib.h
содержит указатели на различные функции
tb_stamp
tb_id -255 для local и 254 для main
td_data -hash fib таблица
struct fn_hash -net/ipv4/fib_hash.c
struct fn_zone *fn_zones[33] -указатели на зоны
struct fn_zone *fn_zone_list указатель на первую не пустую зону
struct fn_zone содержит унформацию про зону и маршруты для неё
struct fib_node ** fz_hash -указывает на хэш записей этой зоны
int fz_nent количество записей
int fx_divisor числу бакетов для зоны (в основном 16 кроме зоны 0000
loopback девайса)
int fz_order индекс зоны в родительской fn_hash
struct fib_node -содержит информацию по девайсу в fib_info(include/net/ip_fib.h
)
метрику ,протокол и т.д
Routing Cache
Это наиболее быстрый способ нахождения маршрута Когда ip нужен маршрут
,то он определяет ячейку в хэше,которая указывает на цепочку маршрутов
и идёт по этой цепочке пока не найдет нужный маршруты имеют таймеры и
частоту использования ,наиболее частые перемещаются в начало.
struct rtable -звено в цепочке
содержит адреса отправителя и получателя
входящий интерфейс
адрес соседа или шлюза
struct dst_entry
содержит спецефические для данного маршрута данные и функциии
struct dev -понятно
pmtu максимальная длина пакета для данного маршрута
int (*input)(struct sk_buff) -указатель на функцию приема для данного маршрута
часто ето tcp_rcv
int (*output)(struct sk_buff) указатель на функцию отсылки (dev_queue_xmit)
также разнообразные стстистические данные и опции
Таким образом нами было проведено исследование сетевой архитектуры
операционной системы Линух на примере реализации стека протоколов
tcp-ip версии 4 в ядре 2.4.7
Приложение
После длительных теотетических изысканий применим их на практике
Нашей целью будет создание удобного пользовательского интерфейса для
указания в пакете подставного ip адреса(адреса которого нет у никакого
нашего интерфейса) Я не буду показывать ,то как адреса выставляются в
ядре.Замечу только то что, из сокетa семейства AF_INET и типа SOCK_RAW
пакет с несвоим адресом отправить вроде бы можно (в ядре 2.2 ,насчет
2.4 неуверен -может там есть какие-то проверки). страницы мана говорят
про опцию IP_HDRINCL .Их можно отправлять также через тип SOCK_PACKET.
Но для всего этого знать код ядра не очень необходимо. Поэтому мы
пойдём други путём.
Наиболее легкий путь(?) сделать это через интерфейс setsockopt. После
внимательного изучения кода функции sys_setsockopt -net/socket.c
находим строки
if ((sock = sockfd_lookup(fd, &err))!=NULL)
{
if (level == SOL_SOCKET)
err=sock_setsockopt(sock,level,optname,optval,optlen);
else
err=sock->ops->setsockopt(sock, level, optname, optval,optlen);
sockfd_put(sock);
}
return err;
}
значит нам надо искать функцию setsockopt в коде для реализации для
типа sock_raw это файл net/ipv4/raw.c смотрим
static int raw_setsockopt(struct sock *sk, int level, int optname,
char *optval, int optlen)
{
if (level != SOL_RAW)
return ip_setsockopt(sk, level, optname, optval, optlen);
...................................
}
функция ip_setsockopt лежит в net/ipv4/ip_sockglue.c в ней идет
длинный перебор опций мы остановим свой выбор на уровне SOL_IP и
добавим в перебор свои строки
/*HACK:>>>>>>>>>>>>>>>*/
#ifdef CONFIG_HACKIP
case IP_HACKIP:
printk("HACKIP:setsockopt flag %d\n",sk->hackflag);
sk->hackflag=1;
get_user(val,(int *) optval);
printk("HACKIP:setsockopt val %d\n",val);
sk->hackf.src_addr=val;
break;
#endif
case IP_HDRINCL:
подробнее опишем происходящие действия
printk -выводим отлабочные сообщения
Я не уверен ,но судя по всему при солздании сокета вся структура
обнуляется поэтому мы можем не смотреть флаг .Я добавил ету строку
,чтоб посмотреть всегда ли он равет 0 при не установленой опции а
после установки при повторе он равен 1. get_user забираем значение
,подробности include/asm/uaccess.h но для всего етого нам надо
добавить соответствующие поля в struct sock
=======sock.h=============
.........................
#ifdef CONFIG_HACKIP
/*HACK:>>>>>>>>>>>>>>>>>>*/
struct ip_hack {
__u32 src_addr;
};
#endif
struct sock {
/* Socket demultiplex comparisons on incoming packets. */
.................................
#ifdef CONFIG_HACKIP
/*HACK:>>>>>>>>>>>>>>>>>*/
struct ip_hack hackf;
int hackflag;
#endif
........................................
===========end======================
теперь нам надо перехватить отправку пакета
идем в файл net/ipv4/ip_output.c и после всех строк где есть
`iph->saddr=` вставляем наш код
#ifdef CONFIG_HACKIP
if((sk->hackf.src_addr!=0)&&(sk->hackflag==1))
{
iph->saddr=sk->hackf.src_addr;
printk("HACKIP:ip_build_and_send.. %d\n",iph->saddr);
}
#endif
Осталось малое: в файл include/linux/in.h добавляем строку #define
IP_HACKIP 16
в файл net/Config.in
bool `HACKIP facilities` CONFIG_HACKIP
делаем
cd /usr/src/linux
make menuconfig
make dep
make bzImage
cp arh/i386/boot/bzImage /boot/kursach
правим lilo.conf или /boot/grub/menu.lst
соответствуюшая команда
reboot....
теперь протестируем нашу программу извиняюсь за возможное наличие
лишних include просто я переделал файл из друго-го проекта
============rel.c========================
/* Written by Gleb Paharenko <gleb@ptf.kiev.ua> 2003 */
/*Посвящяется Кевину Митнику */
/*и прекрасной весне в мае 2003-го*/
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/socket.h>
#include<resolv.h>
#include<arpa/inet.h>
#include<errno.h>
#include<string.h>
#include<linux/ip.h>
#define IP_HACKIP 16
int main()
{
int sd,res;
int value=1;
int sval=0;
int oval=1;
char buffer[100];
struct sockaddr_in addr,raddr;
bzero(buffer,sizeof(buffer));
if((sd=socket(PF_INET,SOCK_RAW,6))<0)
{
perror("Socket");
exit(errno);
}
bzero(&addr,sizeof(addr));
addr.sin_family=AF_INET;
raddr.sin_family=AF_INET;
addr.sin_port=0;
raddr.sin_port=0;
inet_aton("212.168.1.11",(struct sockaddr *)&(addr.sin_addr));
inet_aton("192.168.1.1",(struct sockaddr *)&(raddr.sin_addr));
sval=addr.sin_addr.s_addr;
inet_aton("192.168.1.10",(struct sockaddr *)&(addr.sin_addr));
if(bind(sd,(struct sockaddr *)&addr,sizeof(addr))<0)
{
perror("bind");
exit(errno);
}
if(connect(sd,(struct sockaddr *)&raddr,sizeof(raddr))!=0){
perror("connect");exit(errno);}
/* Вот ОНО!*/
if(setsockopt(sd,SOL_IP,IP_HACKIP,&sval,4)!=0)
{ perror("setsockopt");
exit(errno);
}
send(sd,"Kursovaja",10,0);
}
делаем
# gcc rel.c
#./a.out
#tail /var/log/messages
..................
..................
May 20 00:53:49 kursach -- root[863]: ROOT LOGIN ON tty1
May 20 00:53:51 kursach kernel: HACKIP:setsockopt flag 0
May 20 00:53:51 kursach kernel: HACKIP:setsockopt val 184658132
May 20 00:53:51 kursach kernel: HACKIP:ip_build_and_send.. 184658132
Обьясняю
дома у меня стоит vmware :host-only networking
host machine Windows2000 Professional 192.168.1.1/24
virtual Linux Red-Hat 7.2 "Enigma" 192.168.1.10/24
на 2000 запущен SpyNet
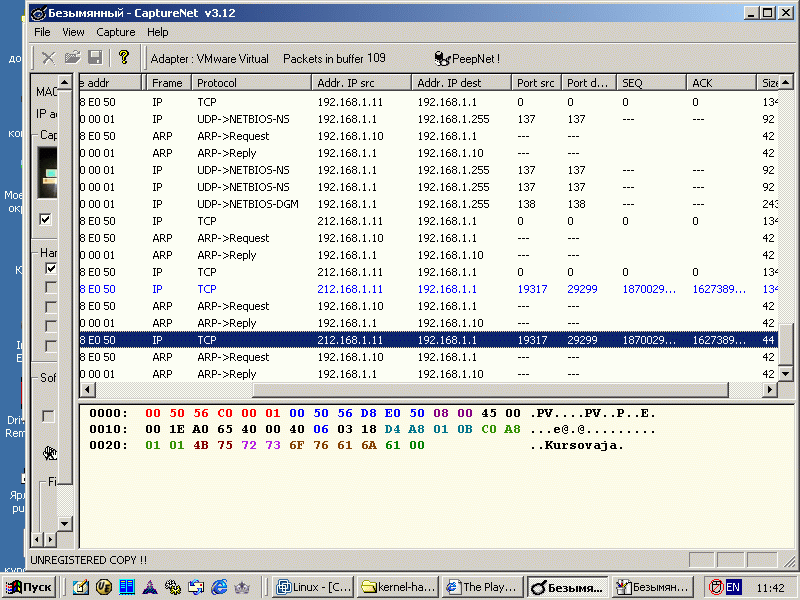
Ловим пакет и...
Работает!!!!!
см рисунок http://www.opennet.ru/soft/kursacj.gif
Заключение
Благодарности
Моим родителям - за понимание и заботу
Glenn Herrin и Computer Science Department networking lab at the
University of New Hampshire -за замечательную статью которую я
использовал(kernelnewbies.org)
Ильину Коле и Арсену Бандуряну - за предоставленую документацию и ПО
Мише Тютину -за то, что познакомил меня с Линухом
Полонскому Лёше,Попову Денису и Корневу Олегу -за предоставленый
интернет
Всем разработчикам Линуха -за замечательную операционную систему и
комментарии к исходным текстам
Написано Глебом Пахаренко в мае 2003-го
пишите мне на gleb@ptf.ntu-kpi.kiev.ua
Теги:
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|
{kind=link}