| Новые программы oszone.net |
Больше полугода мы с нетерпением ждали появления видеокарт нового поколения от корпорации ATI/AMD. За это время мы рассмотрели и протестировали большое количество новейших видеокарт от конкурента – NVIDIA Corporation, и каждый раз нам приходилось оговариваться, что тестирование GeForce 8 в сравнении с видеокартами предыдущего поколения некорректно. Это связано и с тем, что видеокарты создавались с особым уклоном под обработку графики, написанной на DirectX 10, и с тем, что унифицированные шейдерные архитектуры намного лучше справляются с обработкой современной графики, насыщенной шейдерной, то есть математической, обработкой. И вот наконец 14 мая ATI официально представляет новое поколение видеокарт под названием Radeon HD 2000. Теперь мы сможем перестать сравнивать тёплое с мягким, наконец у нас есть видеокарты, выступающие в «одной лиге».
Как видим, так же, как в своё время NVIDIA поступила с префиксом FX, ATI избавляется от префикса X в названиях видеокарт. Вместо него появляются буквы HD. Ход абсолютно логичный: архитектура ядер R6xx абсолютно не похожа на предыдущие поколения и никоим образом не является их эволюционным развитием. Буквы HD символизируют основное направление развития всей индустрии компьютерной (да и не только) графики: разрешения растут, и требуется приемлемая производительность на невообразимых ранее диагоналях мониторов. На способностях Radeon HD 2000 по обработке графики высокого разрешения мы остановимся отдельно. Семейство AMD Radeon HD 2000Что же нам предлагает ATI в новой линейке продукции?
В рамках линейки, как видим, будет довольно большое количество модификаций видеокарт, имеющих разные частоты и оборудованных разными типами памяти. Уже сейчас можно выделить как возможного фаворита Radeon HD 2600XT c высокочастотной памятью GDDR3. Нам кажется несколько неоправданным создание модификации с памятью GDDR4, которая стоит заметно выше предыдущего поколения, греется и потребляет больше энергии, а в условиях 128-битной шины памяти вряд ли раскроет свой потенциал. Впрочем, для того чтобы говорить с уверенностью, нужно сначала увидеть видеокарты в работе. Отметим, что, к сожалению, AMD не удалось сдержать обещания и выпустить на рынок сразу целую линейку видеокарт нового поколения, покрыв все сегменты рынка: 14 мая выходит только Radeon HD 2900XT, а продукты среднего и нижнего ценового диапазонов появятся в продаже в конце июня. Также чуть позже выйдет самая производительная видеокарта новой линейки – Radeon HD 2900XTX, оборудованная 1 Гбайт памяти GDDR4 и способная работать на более высоких частотах. Архитектура Radeon HD 2000Итак, приступим к рассмотрению архитектуры. Сразу оговоримся, что рассматривать мы будем старшую версию ядра, так как младшие не имеют принципиальных различий, кроме уменьшенного числа функциональных блоков.
Архитектура Radeon HD 2000 очень заметно оптимизирована под новое поколение API DirectX. В прошлых поколениях архитектур проектировщикам приходилось искать оптимальное соотношение пиксельных процессоров, выполняющих работу сугубо графического характера, и вершинных, фактически занимающихся математическими вычислениями с плавающей точкой. Это было связано с тем, что раньше весь массив данных проходил по традиционному конвейеру от начала до конца, и при необходимости изменения или повторной обработки приходилось заново всё просчитывать. Теперь можно в любой момент выгрузить данные в память, снова их считать, не дожидаясь конца конвейера, и произвести новые расчёты.
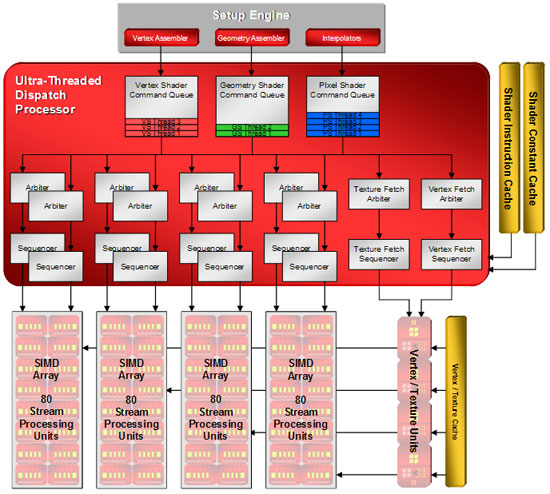
Если проследить эволюцию «соотношений сил» между пиксельными и вершинными конвейерами, то можно заметить, как с течением времени ATI всё больше ориентировалась на математическую работу, то есть вершинные шейдеры. Не зря скорость их обработки была коньком архитектур R4x и R5x. Теперь же с унифицированной шейдерной архитектурой, заложенной в требованиях DirectX 10, не нужно ломать голову над поиском оптимального соотношения, скорость обработки вершин в любой момент может быть повышена за счёт простаивающих пиксельных конвейеров, и наоборот. Семейство Radeon HD 2900 основано на графическом процессоре, разработанном ATI для консоли нового поколения Xbox 360, которое называется Xenos. Как и конкурирующая архитектура G80 от NVIDIA, R600 является суперскалярной архитектурой, ориентированной на параллельное исполнение нескольких потоков данных и в первую очередь математические вычисления. Инженеры использовали почти все выигрышные особенности консольного процессора и развили их. Из сокращений можно отметить разве что отсутствие памяти eDRAM, использовавшейся в Xenos в качестве высокоскоростного кэша. Рассмотрим ядро в порядке прохождения данных по конвейеру. В самом начале обработки в дело вступает командный интерпретатор (Command processor). Он распоряжается загрузкой данных в память, исполняет часть микрокода. В результате оптимизаций AMD заявляет, что нагрузка на процессор, связанная с этими операциями, снижена на 30%. Далее Setup Engine, состоящий из вершинного и геометрического ассемблеров и интерполятора, готовит данные для обработки потоковыми процессорами. Он может исполнять три вида функций: сборку вершин (vertex assembly) и тесселяцию, геометрическую обработку (для нововведения DirectX 10 – Geometry Shaders) и выборку и интерполяцию для пиксельных шейдеров. Затем данные передаются диспетчеру.
На диспетчере следует остановиться отдельно. ATI называет его Ultra-Threaded Dispatch Processor. Он поддерживает раздельные очереди команд для каждого типа шейдеров. Инструкции и данные поступают в диспетчер и распределяются по очередям. Затем данные из очередей передаются на арбитраж. На каждый SIMD-массив приходится по два арбитра, что даёт возможность обрабатывать по 2 потока данных на массив, то есть до 8 потоков одновременно. Для текстур и вершин – свои арбитры. В зависимости от инструкций данные направляются либо на обработку потоковыми процессорами, либо на текстурную выборку и другие текстурные операции в текстурные блоки. В любой момент при возникновении в конвейере данных, имеющих более высокий приоритет, диспетчер может сбросить даже не до конца обработанные данные в кэш и пустить приоритетные данные на обработку. После этого данные, отправленные ранее в кэш, могут быть снова загружены, и обработка продолжится с того места, где остановилась. Это обеспечивается возможностью потоковой обработки данных, предусмотренной DirectX 10, о которой мы уже говорили в статье про GeForce 8800. Для вершинных и пиксельных шейдеров предусмотрены собственные кэши, геометрические шейдеры используют кэш вершинных. При этом объём вершинного кэша увеличен в 8 раз по сравнению с архитектурой Radeon X1950. Наличие кэша инструкций позволяет исполнять шейдеры неограниченной длины с неограниченным числом констант. Диспетчер следит за тем, чтобы исполняющие блоки не простаивали, и при возникновении ситуации, когда обрабатываемые в конвейере данные нуждаются в выборке из памяти или ожидают результатов обработки в другом конвейере, возвращает эти данные в текущем состоянии в очередь и запускает следующие из очереди в обработку. После выполнения условий, необходимых для продолжения обработки, она возобновляется с места остановки.
Теги:
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|