Предприятия собирают массу
информации с помощью ряда методов. Данные поступают по электронной
почте, из опросов, веб-форм и других источников. В общем, данные –
это хорошая
штука. Однако управлять набором
средств сбора данных и массой различной информации непросто.
Надежная интеграция и безопасный общий доступ к данным – постоянная
забота организаций, работающих в сфере информационных технологий.
Развиваются стандарты и архитектуры, ориентированные на службы, и
специалистам по информационным технологиям становится проще более
безопасно делать данные более доступными. Но даже располагая
средствами и технологиями для создания эффективной архитектуры
предприятия, очень легко попасться в сеть закрытых интерфейсов, и
из-за этого решения получаются изолированными.
Например, возьмем технологии Microsoft® Office. С помощью Windows® SharePoint®
Services 3.0 легко создать опрос для подразделения, но будет ли это
решение стандартным, зависит от организации. Если организация
использует ASP.NET и SharePoint как платформу для интеграции данных
и совместной работы в Интернете, то этот опрос будет стандартным
решением. Но если вы работает в такой среде, как я, SharePoint –
всего лишь одна платформа из многих.
Конечно, SharePoint дает широкие возможности
интеграции с системами от IBM, HP, Siebel и так далее. Это хорошо
для опытных пользователей, которые хотят создать простое решение,
позволяющее, тем не менее, направлять данные в несколько конечных
систем. Но если вы архитектор решения, есть способ еще лучше –
InfoPath® 2007.
С помощью InfoPath 2007, входящего в систему
Office 2007, можно разделить в своем решении логику представления от
логики управления информацией, находящейся на серверах. С помощью
технологии InfoPath, основанной на XML, можно создавать решения для
сбора данных для всего предприятия. И, главным образом, разработчики
форм InfoPath не должны подробно знать XML, веб-службы, архитектуры
решений, ASP.NET или объектную модель SharePoint.
В этой статье я расскажу, как создать гибкое
решение для сбора данных с помощью InfoPath 2007, Office SharePoint
Server 2007 и Forms Services. Я покажу вам, как XML позволяет
разделить логику представления от логики организации в многоярусной
архитектуре предприятия.
Заметьте, что под «сбором данных» я имею в виду
процесс получения информации от людей. Конечно, есть другие способы
собирать данные, такие, как обход источников данных, но эти
автоматизированые методы выходят за рамки этой статьи.
Сбор и обработка
данных
Требования к получению данных могут быть
сложными, но эти процессы имеют кое-что общее. Пользуясь этими
сходствами в централизованных модулях при выполнении уникальных
требований в децентрализованных компонентах, можно ограничить
избыточную работу, издержки поддержания и общую стоимость
владения.
Например, требования соответствия нормативам для
открытых акционерных обществ приводят к требованиям бизнеса,
которые, в свою очередь, обуславливают политику управления
информацией в масштабах компании. Эта политика влияет на решения для
сбора данных с многих отделов и часто ведет к повторению одинаковых
действий в разных отделах; например, правила сбора личных сведений,
получаемых отделом трудовых ресурсов (оработка информации о
сотрудниках) и отдел работы с клиентами (обработка информации о
клиентах). Даже бизнес-процессы, происходящие между разными
сходными, но не имеющими друг к другу отношения отделами позволяют
унифицировать решения для управления информацией.
На рис. 1 приведен
пример типичного бизнес-процесса. Сотрудник, который хочет
обменяться задачей с коллегой, должен в первую очередь получить
согласие коллеги, затем одобрение ответственного лица или
координатора графика работы и, наконец, руководителя. Например,
сотрудники могут меняться сменами. Хотя эти обмены происходят в
различных отделах и могут принимать различные формы, рабочие потоки
и логика управления информацией могут быть общие для различных
решений в отделах.
 Рис.
1 Пример процесса сбора данных,
который может быть общим для различных отделов
Рис.
1 Пример процесса сбора данных,
который может быть общим для различных отделов
Конечно, объединение избыточных компонентов – это
трудная задача. Изменить организацию работы в компании непросто, но
технологии системы Office позволят заложить надежную основу для
таких изменений. InfoPath 2007 позволяет отделам создавать
приложения на основе форм, которые интегрируются в централизованные,
стандартизированные системы управления информацией. SharePoint 2007,
между тем, позволяет отделам информационных технологий передавать
административное управление наборами веб-узлов, веб-узлами и
библиотеками документов определенным отделам и группам. Таким
образом, группы могут создавать и развертывать собственные решения
независимо от отдела информационных технологий, а этот отдел
сохраняет контроль над всеми общими службами и компонентами, такими,
как рабочие потоки, политика управления информацией и процедуры
резервного копирования.
Централизация работы по сбору данных
Часто для групп создаются серверы приложений для
удовлетворения локальных нужд управления информацией. Отдел
информационных технологий просто отвечает за обеспечение
работоспособности оборудования и операционной системы, а отделы сами
занимаются всеми аспектами своих решений. Координация между отделами
невелика, и обмен информацией затруднен.
Технические трудности при централизации сбора
данных в основном касаются безопасности, производительности,
поддержания и обеспечения работы пользовательских компонентов в
общей среде. Например, если индвидуальные решения размещаются на
серверах приложений отделов, эффекты неработающего компонента
изолированы. Однако в общей среде неработающий компонент может
привести к более масштбаным последствиям для бизнес-процессов.
Следовательно, отдел информационных технологий должен устанавливать
строгие ограничения на развертывание и поддержание пользовательских
компонентов в централизованных системах.
Размещение решений SharePoint по отделам на
центральной ферме серверов требует развертывания и поддержания всех
пользовательских компонентов этих решений на центральных серверах
приложений. Одно решение может зависеть от пользовательских типов
полей, которые увеличивают пользовательский интерфейс решения за
счет раскрывающихся списков, наполняемых из веб-служб,
взаимодействующих с пользователем. Другое может использовать для той
же цели веб-компоненты, а еще одно может использовать
пользовательские рабочие потоки – и те, и другие написаны в
управляемом коде и развертываются как сборки Microsoft .NET
Framework.
Перемещение даже небольшого числа решений
SharePoint на ферму центральных серверов приложений может привести к
серьезным проблемам настройки и поддержки. Если сборки необходимо
развертывать в глобальном кэше сборок (Global Assembly Cache, GAC),
возникают проблемы с безопасностью, так как такие сборки работают с
полным доверием. Плохо написанные компоненты могут открыть систему
для атак с помощью введения SQL, межузловых сценариев или отказа в
обслуживании. Необходимо обеспечить компонентам возможность
выдерживать как стандартную, так и пиковую нагрузку и выполнение
длительных операций. Следует убедиться, что компоненты не блокируют
при одновременном использовании событий другие процессы и что
компоненты выполняют надежную проверку ввода, чтобы пользователи не
могли вставлять в колонки для обновления базы данных или удаленной
веб-системы операторы SQL или сценарии.
Одним словом, задача состоит в создании надежной
и масштабируемой серверной конфигурации на основе стандартных
функций продукта. Опираясь на тщательно проверенные, универсальные
решения, можно избежать ловушки многочисленных пользовательских
компонентов. Логично держать клиентскую часть децентрализованной, а
серверную – централизованной. Главное – интегрировать компоненты
слабо связанным образом, позволяющим повторное использование
существующих решений
Разделение бизнес-логики
Итак, как же создавать гибкие решения для сбора
данных, которые можно настроить на своих серверах? Лучшая стратегия
– разделить архитектуру решения на отдельные уровни, как показано на
рис. 2: хранилище данных, бизнес-логикуи
представление или пользовательский интерфейс. Сегодня
пользовательские интерфейсы обычно основаны на обозревателях, а
бизнес-логика располагается на серверах веб-приложений. Они, в свою
очередь, используют базы данных и нереляционные хранилища даных.
 Рис.
2 Типичное решение для
предприятия, созданное на основе трехуровневой архитектуры
Рис.
2 Типичное решение для
предприятия, созданное на основе трехуровневой архитектуры
В состав бизнес-логики часто входит логика
транзакций, обеспечивающая элементарность выополнения транзакций
между системами управления базами данных. В бизнес-логику могут
также встраиваться различные службы среднего уровня через HTTP,
очередь сообщений, RPC и так далее. Однако общая архитектура решения
остается трехуровневой.
Но на рис. 2 не видна
сложность бизнес-логики в условиях предприятия. Сервер приложений на
этом рисунке как бы просто занят выводом формы на основе
обозревателя и обработкой полученных данных; но ведь эта схема не
принимает в расчет рабочие потоки, соответствие или требования
управления информацией. Чтобы справиться с этим, придется разделить
логику пополам – на логику представления и логику управления
информацией. Это позволит перемещать и сопоставлять компоненты
среднего уровня по желанию, не перестраивая заново компоненты для
каждого решения.
Эта архитектура показана на рис. 3. В центре –
содержимое или данные, окруженные логикой управления информацией,
контролирующей содержимое все время его существования. Логика
представления объединяется с логикой управления нформацией, чтобы
обеспечить доступ к данным через пользовательский интерфейс.
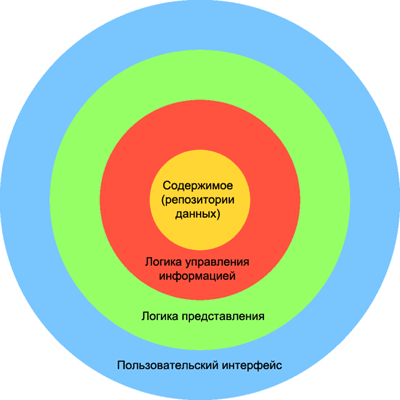
Рис. 3 Отделение логики представления от логики управления
информацией
Сбор и обработка XML
В средах приложений, ориентированных на службы
(service-oriented application, SOA), XML – основной стандарт,
использующийся для определения и совместного использования
компонентами данных и стуктур данных. Поэтому XML – хороший вариант
для связи компонентов представления и управления информацией.
Связь должна проходить в двух направлениях:
необходимо перевести XML в документ, распознаваемый обозревателем, и
в документ XML, создаваемый формой. До последнего времени создание
приложений на основе форм в XML требовало большого опыта
программирования. Это было особенно важно, когда данные в XML должны
были соответствовать общей схеме предприятия, чтобы обеспечить
внутренний обмен информацией.
Благодаря InfoPath 2007 разработка форм на основе
XML стала гораздо проще. Хорошее знание XML определенно не помешает,
но разработчики форм и пользователи не обязаны творить чудеса, чтобы
создавать приложения на основе форм в XML. Разработчик формы просто
импортирует документ или схему на XML в InfoPath, а затем
устанавливает соответствие между отдельными узлами атрибутов и
элементов этого источника данных и полей формы. Разработчик может
также начать с веб-службы, базы данных SQL Server® или с чистого шаблона, создавая форму с нуля,
а InfoPath автоматически в фоновом режиме создает схему и привязки
данных.
Стандартизация форм с помощью InfoPath и схем XML
имеет несколько преимуществ. Если у вас уже есть хорошо определенная
схема на XML, проектировщики форм и разработчики рабочих потоков и
компонентов управления информацией могут создавать решения с теми же
структурами данных. Если проектировщик форм начинает с нуля,
разработчикам приходится ждать, пока форма будет готова, чтобы знть,
как она влияет на подлежащие структуры данных. После определения
структур данных последующие решения, такие как новые шаблоны форм,
могут использовать существующие рабочие потоки и компоненты
управления информацией, если они опираются на те же структуры
данных. А последующие рабочие потоки и компоненты управления
информацией могут работать совместно с существующими формами и
данными. Если создавать решения для сбора данных на основе
устоявшихся отраслевых схем, результаты получаются еще более
гибкими. Эти решения будут совместимы с решениями, создаваемыми
другими компаниями, использующими те же схемы.
Я создал простую схему DirectReports, связывающую
сотрудников с ответственными лицами. Ответственные лица могут
использовать получаемые формы, чтобы рассчтывать прямые отчеты.
Схему, форму и файл readme.htm с указаниями для создания формы можно
найти в папке Direct Reports в загружаемом приложении к этой статье
на странице technetmagazine.com/code08.aspx.
Это простая форма, иллюстрирующая общий принцип.
Важная вещь: я не создавал логики проверки в
InfoPath, но InfoPath требует, чтобы идентификатор пользователя и
адреса электронной почты вводились в определенном формате
(домен\учетная запись и recipient@domain.tld). В противном случае
итоговый документ XML будет недопустимым. Это связано с тем, что
схема XML определяет такие форматы. Форму с недопустимыми данными
можно сохранить, но ее нельзя обработать; это показано на рис. 4. (Я добавил в форму заглушку вместо
правила обработки, так что это можно проверить, не направляя в
действительности данные в какое-либо место.) Проверка InfoPath 2007
автоматически гарантирует правильность заполнения формы.
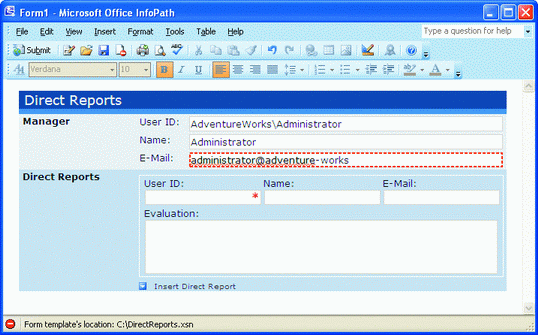
Рис.
4а Ошибки проверки не позволяют
пользователю отправить форму
 Рис.
4б Создаваемое сообщение об ошибке
Рис.
4б Создаваемое сообщение об ошибке
Схема XML служит связующим звеном между лоигкой
представления и логикой управления информацией. InfoPath блокирует
схему, чтобы разработчик форм не мог изменить структуры данных. Это
важно, так как изменение принятой схемы XML может нарушить работу
существующих решений на предприятии, таких, как модули рабочих
потоков, которые вы собираетесь использовать вместе с новым шаблоном
форм.
InfoPath имеет множество функций, позволяющих
реализовать сложную логику представления в приложениях на основе
форм. Чтобы получить осмысленные значения по умолчанию, можно
использовать данные из файлов XML, веб-служб, библиотек и списков
SharePoint, баз данных и так далее. Можно изменять значения полей в
зависимости от выбора пользователя (с помощью правил), добавлять
управляемый код для выполнения сложнейших дополнительных условий и
использовать службу форм для обеспечения доступа к формам через
Интернет. В любом случае форма с данными в некий момент входит в
логику управления информацией как документ XML, удовлетворяющий
определению схемы.
Работа с XML или метаданными
Следует ли применять логику управления
информацией прямо к отправленному документу XML или использовать
анализатор, извлекающий нужную информацию в метаданные? SharePoint
поддерживает оба варианта. Разработчики обычно используют документы
XML, но метаданные дают больше гибкости.
Чтобы это проиллюстировать, я создал простую
веб-службу, анализирующую документ XML, передаваемый из формы Direct
Reports, показанной на рис. 4. (Исходный
код, файлы установки и readme.htm с пошаговыми указаниями находятся
в папке XMLParsingWebService folder в загружаемом приложении.)
Веб-служба просто считывает идентификатор пользователя
ответственного лица из документа XML, разделяет его на имя домена и
имя пользователя, создает на их основе сообщение и затем вызывает
стандартное исключение, отображающее обработанную информацию в виде
псевдосообщения об ошибке в форме InfoPath. Это простой способ
открыть в InfoPath диалоговое окно после отправки данных. Веб-служба
работает отлично, но если изменить источник данных (например,
переименовать в DirectReports.xsd элемент OrgPerson в Manager и
обновить форму InfoPath при помощи новой схемы, согласно указаниям в
файле readme.htm), веб-служба выдаст ошибку. Ничего удивительного.
Документ XML изменился, и старое выражение XPath для доступа к
элементу user-id стало неверным. Схемы OrgPerson и Manager
практически одинаковы, формы InfoPath идентичны, ожидаемые
результаты обработки те же, но несмотря на минимальные различия,
придется разворачивать и поддерживать дублирующиеся веб-службы.
Если вы хотите уменьшить количество
дополнительного кода на серверах приложений, этот подход плох.
Напротив, если связать узлы XML с полями метаданных и проводить
обработку на основе метаданных, можно использовать те же рабочие
потоки и логику управления информацией для сходных структур данных,
даже если схемы XML отличаются. Нужно лишь убедиться, что дочерный
элемент соответствует правильному полю метаданных и что формат
данных соответствует требованиям обработки; тогда можно использовать
уже существующий код.
Связь узлов XML с полями метаданных
устанавливается аналогично связи узлов XML с элементами управления
пользовательского интерфейса в форме InfoPath form, как показано
на рис. 5. В SharePoint поля метаданных
соответствуют столбцам, определяемым на уровне веб-узла или списка и
имеющим ссылки в определениях типов содержимого. Типы содержимого
определяют свойства элементов содержимого, таких как поля
метаданных, рабочие потоки и формы. Для синхронизации полей
метаданных типа содержимого с соответствующими узлами документа XML,
SharePoint использует встроенный анализатор XML, выполяющий внесение
и извлечение свойств. При внесении свойств, анализатор XML извлекает
значения узлов из документа XML в соответствующие столбцы библиотеки
документа. Извлечение свойств – это обратный процесс, при котором
значения столбцов извлекаются из библиотеки документа и записываются
обратно в документ. Самое главное, что анализатор XML обеспечивает
синхронизацию полей метаданных и связанных узлов XML.
 Рис.
5 Связь схемы XML между InfoPath и
SharePoint
Рис.
5 Связь схемы XML между InfoPath и
SharePoint
При использовании модели объекта SharePoint
веб-компоненты, рабочие потоки и логика управления информацией могут
работать как с полями метаданных, так и с лежащими в основе
документами XML. Изменение значения поля метаданных влечет за собой
изменение значения узла в документе XML и наоборот. В то же время,
работа напрямую с документом XML связывает бизнес-логику со схемой
XML. Поля метаданных, напротив, увеличивают возможности повтороного
применения кода. Конечно, всегда нужно решать, какой подход больше
подходит в данной среде, но чаще всего решения SharePoint,
использующие поля метаданных, дают больше гибкости и возможностей
повторного использования кода.
Чтобы показать, как SharePoint связывает узлы XML
с полями метаданных, я включил в сопровождающий материал функцию
SharePoint, обеспечивающую пользовательскую библиотеку документа
(см. файл OrgPersonContentType.xml в папке OrgPersonLib в
загружаемом приложении). Тип содержимого OrgPerson содержит ссылки
на четыре поля: UserID, FullName, EMail и Direct_x0020_Reports.
FullName и EMail – встроенные поля. UserID и Direct_x0020_Reports –
пользовательские поля, определяемые в OrgPersonSiteColumns.xml.
Определения полей довольно просты. В определениях
полей можно привязывать поля прямо к узлам XML, но эту информацию
можно также перезаписать в типах содержимого. Я выбрал второй
вариант, так как он позволяет использовать пользовательские поля как
в типах содержимого, не имеющих отношения к документам XML, так и в
типах, использующих различные структуры XML. Тип содержимого
OrgPerson привязывает поля метаданных к узлам XML, которые по своей
организации соответствуют упомянутой ранее схеме OrgPerson. Также
есть файл AdditionalContentTypes.xml, определяющий дополнительные
типы содержимого, связывающие те же поля метаданных с другими узлами
XML. Различия видны в выражениях XPath в атрибутах Node.
Библиотеки документов в типе OrgPersonLib могут
хранить различные типы документов XML, а значения узлов отражаются в
одних и тех же столбцах библиотеки. Этот простой прием сопоставления
позволяет повторно применять рабочие потоки и логику управления
инфорацией, так как четыре типа содержимого (OrgPerson, Manager,
Supervisor и User) ссылаются на общий набор полей метаданных.
На рис. 6 показан элемент FieldRef из типа
содержимого OrgPerson для Direct_x0020_Reports, который сопоставляет
поле и узлы user-id прямых отчетов в соответствии с выражением
XPath, /OrgPerson/direct-report/user-id. Так как документ XML может
содержать несколько экземпляров прямых отчетов, важно указать
атрибут Aggregation. Он определяет, как анализатор XML обрабатывает
возвращаемый набор значений. Если опустить этот атрибут, анализатор
XML извлекает только первое значение узла. Поддерживаемые значения
объединения – sum, count, average, min, max, merge, plain text,
first, и last.
 Рис.
6 Поля метаданных, сопоставленные
с выражением XPath
Рис.
6 Поля метаданных, сопоставленные
с выражением XPath
Все приведенные типы содержимого используют
стандартную страницу upload.aspx в качестве DocumentTemplate, так
что файлы XML можно загружать в библиотеку докментов при нажатии
кнопки «Создать» (New) в пользовательском интерфейсе SharePoint.
Если вы загружаете файлы с расширением .xml, SharePoint
автоматически вызовает встроенный анализатор XML (исключение – файлы
WordProcessingML, для которых SharePoint вызывает анализатор
WordProcessingML). Анализатор XML изучает загруженный файл .xml и
определяет соответствующий тип содержимого. Так он может извлечь
значения узлов из указанных в определениях полей мест и выполнить
внесение свойств. (Этот процесс можно проверить, загружая файл
OrgPerson.xml из папки OrgPersonLib\XMLFiles.) Структура этого
документа XML соответствует выражениям XPath, указанным в
определении типа содержимого OrgPerson. Таким образом, SharePoint
извлекает данные из файла .xml, записывает данные в соответствующие
столбцы библиотеки и отображает данные на странице EditForm.aspx,
позволяя проверить и обновить те свойства документа, которые не
помечены как «доступные только для чтения». На рис. 7 показана форма EditForm.aspx с данными,
извлеченными из OrgPerson.xml.
 Рис.
7 Форма EditForm.aspx с
извлеченными данными
Рис.
7 Форма EditForm.aspx с
извлеченными данными
При изменении значений User ID, Full Name или
E-Mail в EditForm.aspx SharePoint выполняет извлечение свойств,
изменяя значения узлов в подлежащем документе XML. Обратите
внимание, однако, что SharePoint не применяет ограничений схемы XML,
если вы сами не реализуете нужную логику в форме.
SharePoint также не применяет логику
представления приложения на основе форм. Например, при изменении
User ID, SharePoint не проверяет, соответствует ли новое значение
правилам NetBIOS, и не обновляет автоматически поля Full Name и
E-Mail, чтобы они соотвествовали новому выбору. Поэтому, если
изменение отдельного поля может вызвать несоответствия, то этот
столбец следует пометить как «только для чтения» в определении типа
содержимого. Это вынуждает пользователя для обновления данных
применять приложение на основе форм, такое как InfoPath, а
анализатор XML перенесет любые изменения из документа XML в
соответствующие поля метаданных в SharePoint.
В примере OrgPersonLibsample можно загрузить
любой из файлов .xml из папки OrgPersonLib\XMLFiles. Файлы .xml
используют очень разные структуры данных, но SharePoint распознает
типы содержимого и вносит правильные значения узлов в столбцы
веб-узла. Это связано с тем, что я применил в файлах XML инструкцию
по обработке, предписывающую сопоставлять документы XML с
соответствующими типами содержимого. Файл OrgPerson.xml, однако, не
содержит этой информации, но это не беда. Если SharePoint не может
сопоставить документ XML с типом содержимого с помощью инструкции по
обработке или шаблона документа, SharePoint использует тип
содержимого по умолчанию. В случае OrgPersonLib, это тип содержимого
OrgPerson, таким образом, документ XML анализируется правильно.
На рис. 8 показано, как непосредственно связать
документ XML с типом содержимого. Инструкция по обработке
MicrosoftWindowsSharePointServices определяет ContentTypeID как
0x010100668E393E4F0EFF4294DBD202D5D8321D. Это идентификатор типа
содержимого User, определяется это в AdditionalContentTypes.xml.
 Рис.
8 Инструкции по обработке и данные
XML файла User.xml
Рис.
8 Инструкции по обработке и данные
XML файла User.xml
Анализатор XML обрабатывает инструкцию по
обработке MicrosoftWindowsSharePointServices и записывает значение
ContentTypeID с поле метаданных ContentType. Все типы содержимого
SharePoint имеют это поле метаданных, так как оно определяется на
корневом уровне в типе содержимого System. Если открыть файл
fieldswss.xml на сервере SharePoint (в папке
%CommonProgramFiles%\Microsoft Shared\Web Server
Extensions\12\Template\Features\) и выполнить поиск
MicrosoftWindowsSharePointServices, можно увидеть, как SharePoint
сопоставляет инструкцию по обработке с полем ContentType. Атрибут
PITarget указывает на MicrosoftWindowsSharePointServices (это
инструкция по обработке), а PIAttribute указывает на ContentTypeID
(содержащий идентификатор типа содержимого User).
Сопоставления типов содержимого в
InfoPath
Техническая сторона анализа XML и сопоставлений
типов содержимого может затруднять многих разработчиков форм; но
InfoPath 2007 позаботится о всех мельчайших деталях. Файл
readme.htm, сопровождающий пример OrgPersonLib, включает инструкции
для публикации в SharePoint шаблона формы Direct Reports и создания
типа содержимого, который опять связывается ес теми же полями
метаданных (UserID, FullName, EMail и Direct_x0020_Reports). В
пользовательском интерфейсе SharePoint можно легко добавить новый
тип содержимого в библиотеку документов OrgPersonLib. Но новый тип
содержимого также указывает на шаблон формы InfoPath как на шаблон
документа, вызывающего приложение на основе форм при обновлении
существующих документов XML. На рис. 9
показано, как мастер публикации InfoPath упрощает сопоставление
свойств между значениями узлов XML и столбцами веб-узла SharePoint.
И, еще раз, если вы сопоставляете значения узлов с существующими
столбцами веб-узла, можно повторно использовать существующие
компоненты SharePoint.
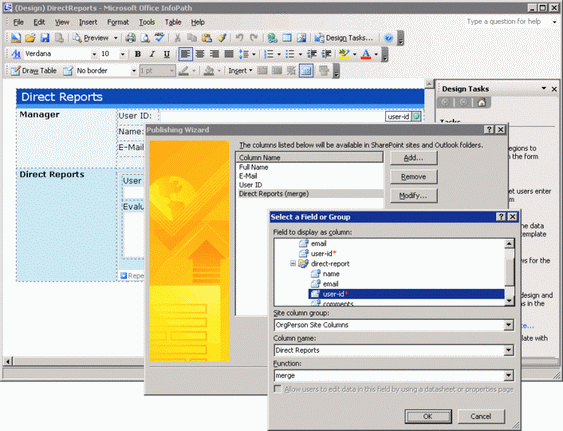
Рис.
9 Сопоставление свойств в InfoPath
2007
Заключение
С помощью технологий Office, архитекторы
предприятия могут создавать решения по сбору данных, которые
обеспечивают повторное использование кода и обмен информацией.
InfoPath 2007 позволяет отделам создавать решения, собирающие
информацию из различных источников, а данные затем можно подавать в
различные системы, такие, как SharePoint. SharePoint обеспечивает
разработчикам полный набор веб-служб и интерфейсов для создания
рабочих потоков и компонентов управления информацией. Разместив эти
компоненты на централизованных серверах SharePoint, отделы получают
инфраструктуру, необходимую для создания собственных приложений.
При этом отделы могут создавать свои решения по
сбору данных быстрее. Требования соответствия нормативам и другие
глобальные требования бизнеса могут вполняться на уровне над
отделами, а поддерживаемость и надежность информационной среды
увеличивается за счет использования меньшего числа пользовательских
компонентов на серверах приложений.