| Новые программы oszone.net |
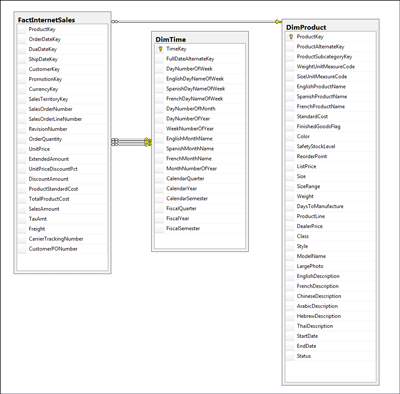
SQL Server 2008 предложит более мощные возможности надежного хранения данных, чем его предшественник, но, возможно, вы все еще гадаете, как можно использовать все эти новые технологии для создания производительного хранилища данных для поддержки решения более миллиарда строк. Вы, возможно, также хотите узнать, какие функции помогут получить лучшую производительность для запросов и отчетов поддержки решений и каких улучшений производительности следует ожидать от новой версии SQL Server®. По мере приближения итогового выпуска, накапливается все больше вопросов. Мы надеемся, что этот подробный обзор некоторых важнейших функций хранения данных SQL Server 2008, связанных с производительностью, поможет вам подготовиться. Логическая структура базы данных: многомерное моделированиеТранзакционные бизнес-приложения обычно имеют нормализованную схему базы данных. Логическая структура схемы базы данных для реляционных хранилищ данных не так связана с нормализацией. Многие современные структуры реляционных хранилищ данных основаны на подходе многомерного моделирования, который стал популярен после выхода книги Ральфа Кимбалла (Ralph Kimball) и Марджи Росс (Margy Ross) «The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling» (Инструментарий хранилища данных: полное руководство по многомерному моделированию). Те, кто работает с хранилищами данных, наверняка знакомы с обычными схемами для реляционных хранилищ данных (такие, как «звезда» и «снежинка»). В многомерном моделировании выделяются таблицы измерений и таблицы фактов. Таблицы измерений содержат основные данные (продукты, клиенты, магазины или страны), а таблицы фактов содержат данные транзакций (продажи, заказы, покупки или возвраты). Таблицы измерений и фактов имеют связь «первичный (PK)-внешний (FK) ключ». Многие хранилища данных не используют ограничения FK для уменьшения требований к объему хранилища. Это спасает от дополнительных затрат на хранение подлежащих индексов и сокращает стоимость поддержания таблицы фактов. Таблицы измерений в хранилище данных обычно небольшие, они содержат в среднем тысячи и до нескольких миллионов строк. Таблицы фактов, с другой стороны, могут быть очень большими и содержать от сотен миллионов до миллиардов строк. Поэтому логическая структура должна уделять особое внимание требованиям таблицы фактов к объему хранилища. Этот фактор размера влияет на то, какой ключ следует выбрать из таблицы измерений, чтобы поддерживать соотношения таблицы фактов к таблице измерения. Составные ключи, основанные на бизнес-ключе измерения (то есть на реальном идентификаторе объекта, представленного измерением), обычно занимают несколько столбцов. Следует знать, что это проблема для соответствующего внешнего ключа в таблице фактов, потому что составной ключ из нескольких столбцов будет повторяться для каждой строки таблицы фактов. Чтобы этого не было, для реализации отношений между таблицей фактов и ее измерениями часто применяют маленькие суррогатные ключи. Суррогатный ключ – это столбец идентификаторов типа integer, который служит искусственным первичным ключом таблицы измерения. Большие таблицы фактов, ссылающиеся на маленькие суррогатные ключи, требуют гораздо меньше места. На Рис. 1 показана схема хранилища данных на основе многомерной модели, использующая таблицы фактов и измерений с суррогатными ключами.
Рис. 1 Пример схемы «звезда» с таблицей фактов и двумя таблицами измерений Схема «снежинка» распространяет одно или несколько измерений на множество уровней (например, клиент, страна и регион для измерения «клиент»), нормализуя большие измерения, которые могут быть перегружены избыточными данными. Уровни представлены отдельными таблицами, поэтому схема похожа на снежинку. Структура схемы «звезда», напротив, не распространяет измерения на таблицы. Эта схема имеет форму звезды, где центром служит таблица фактов, а вокруг нее собраны таблицы измерений. В схемах "звезда" или «снежинка», смоделированных многомерно, запросы поддержки решения следуют такой типичной последовательности: запрос выбирает несколько нужных мер из таблицы фактов, объединяет строки фактов с одним или несколькими измерениями вместе с суррогатными ключами, размещает предикаты фильтров в бизнес-столбцы таблиц измерений, группирует по одной или нескольким бизнес-столбцам и собирает меры, полученные из таблицы фактов за промежуток времени. Ниже приведена эта последовательность, которую иногда называют «запрос типа ‘звезда’»: select ProductAlternateKey,
CalendarYear,sum(SalesAmount)
from FactInternetSales Fact
join DimTime
on Fact.OrderDateKey = TimeKey
join DimProduct
on DimProduct.ProductKey =
Fact.ProductKey
where CalendarYear between 2003 and 2004
and ProductAlternateKey like 'BK%'
group by ProductAlternateKey,CalendarYear
Физическая модельМногие запросы SQL в реляционном хранилище данных следуют такой структуре запроса типа «звезда». Тем не менее, запросы поддержки решения меняются со временем, потому что руководители постоянно пытаются улучшить понимание фундаментальных данных бизнеса новыми способами. Именно поэтому в рабочих нагрузках на хранилища данных много незапланированных запросов. Это усложняет физическую модель запросов поддержки решения и схемы многомерно смоделированного хранилища данных. Обычно под SQL Server разработчики хранилищ данных начинают с плана или физической модели, которую они улучшают и корректируют по мере развития рабочей нагрузки. Вы можете воспользоваться таким планом для собственной среды хранилища данных. В этом случае, не забывайте о рекомендациях для построения физических моделей баз данных, таких, как воздействие на скорость за счет поддержания индексов для обновления и требования индексов к объему хранилища. Таблица фактовПлан должен быть расчитан на типичную форму запроса «звезда» и он должен строить индексы на таблице фактов. Кластеризованный индекс таблицы фактов использует несколько столбцов суррогатных ключей измерений (столбцы внешнего ключа) в качестве ключей индекса. Столбцы, используемые чаще всего, должны появиться в списке ключей индекса. Не помешает проверить, что таким образом действительно получаются хорошие пути доступа для наиболее частых запросов в рабочей нагрузке. Кроме того, план создает некластеризованный индекс в один столбец для каждого столбца суррогата измерения (внешнего ключа) в таблице фактов. Это обеспечивает высокоэффективный путь доступа для запросов, очень избирательных в одном из измерений. Задача кластеризованного индекса – обеспечить хорошую производительность для большинства запросов рабочей нагрузки. Набор некластеризованных индексов предназначен для запросов, получающих меры таблицы фактов для определенного клиента или продукта. Эти некластеризованные индексы исключают, например, сканирование всей таблицы фактов при поиске данных о продажах одному клиенту. Таблица измеренийПрименяя план к таблицам измерений, нужно создавать индексы для каждой таблицы измерения. Это некластеризованный индекс ограничения первичного ключа на столбце суррогатного ключа измерения и кластеризованный индекс столбцов бизнес-ключа объекта измерения. Для больших таблиц измерений можно добавить некластеризованные индексы для столбцов, которые часто используются в очень избирательных предикатах. Кластеризованный индекс увеличивает эффективность извлечения, преобразования и загрузки (ETL) в период обслуживания хранилища данных, которое часто ограничено во времени. Например, в случае медленно меняющихся измерений, существующие строки обновляются на месте, а новые – добавляются к таблице измерения. Такая схема доступа может быть эффективной только при хороших просмотре и обновлении таблицы измерения во время ETL. План, описанный выше, служит хорошей отправной точкой для физических моделей реляционных хранилищ данных на SQL Server. Основываясь на этом типичном устройстве реляционного хранилища данных, мы можем рассмотреть ключевые новые функции SQL Server 2008. Оптимизация запроса типа «звезда»Обработка таблицы фактов – обычно самая продолжительная часть выполнения запроса «звезда» в реляционном хранилище данных на многомерной модели. В этом легко убедиться, потому что даже очень избирательные запросы получают на порядок больше строк из таблицы фактов, нежели из любого измерения. Поэтому использование наилучшего пути доступа в таблицу фактов важно для высокой производительности запроса. SQL Server использует оптимизатор запроса на основе стоимости, то есть пытается создать план выполнения с минимальной оценочной стоимостью. В контексте хранения данных, главная задача -- убедиться, что оптимизатор запроса оценивает однозначные альтернативы путей доступа для плана выполнения запроса "звезда». В оптимизатор запросов SQL Server включено несколько функций, автоматически обеспечивающих производительные планы выполнения запросов типа «звезда». Запросы типа «звезда» можно представить себе разделенными на три класса, как на рис. 2. Эти широкие классы также позволяют SQL Server определять правильные планы для таких запросов. SQL Server основан на главном принципе избирательности запросов по отношению к таблице фактов. Запрос тем более избирателен, чем меньше строк из таблицы фактов он употребляет. Проценты строк, полученных из таблицы фактов, используются для создания классов запросов. Эти проценты отражают значения из типичных запросов клиентов, но не являются строгими границами для создания определений пути доступа.
Figure 2 Диапазоны избирательности для запросов типа «звезда» В первый класс включены высокоизбирательные запросы, обрабатывающие до 10 процентов строк таблицы фактов. Второй класс, со средней избирательностью, содержит запросы, обрабатывающие от 10 до 75 процентов строк таблицы фактов. Запросы в третьем классе, с низкой избирательностью, требуют обработки более 75 процентов строк таблицы фактов. Прямоугольники на рисунке показывают основные планы выполнения запросов для каждого класса избирательности. Выбор плана на основании изибрательностиТак как высокоизбирательные запросы «звезда» обычно получают не более 10 процентов строк таблицы фактов, им можн позволить случайный доступ к таблице. Поэтому планы запросов для этого класса основаны на соединениях вложенных циклов вместе с поисками индексов (некластеризованных) и поиском закладок в таблице фактов. Так как они выполняют произвольный ввод/вывод в таблицу фактов, последовательный ввод/вывод, при получении больших количеств таблицы фактов, получается более производительным. Поэтому по мере роста количества строк, получаемых из таблицы фактов, выше определенного предела, применяется другой план запроса. Так как запросы типа «звезда» средней избирательности обрабатывают значительную часть строк таблицы фактов, для доступа в таблицу фактов обычно применяются хэш-соединения со сканированием таблицы фактов или сканирование диапазона таблицы фактов. SQL Server использует растровые фильтры для улучшения производительности хэш-соединений. На рис. 3 показано, как SQL Server использует растровые фильтры для улучшения производительности соединения при выполнении запроса типа «звезда». На рисунке показан план запроса к двум таблицам измерений, продукта и времени, которые соединяются с таблицей фактов через суррогатные ключи. Запрос использует предикаты фильтров, такие, как оператор WHERE, против обоих таблиц измерений так, что только одна строка подходит для каждого измерения. Это обозначано маленькими красными таблицами рядом с двумя операторами соединения.
Рис 3 План запроса типа «звезда» с обработкой уменьшения соединения Реализация соединения для каждого соединения – хэш-соединение, которое позволяет SQL Server взять информацию о соответствующих строках из таблиц измерений и получить то, что мы называем информацией об уменьшении соединения, для обоих таблиц измерений. Зелеными рамками на рисунке обозначены структуры данных информации об уменьшении соединения. Заполнив их из подлежащих таблиц измерений, SQL Server автоматически передает во время выполнения запроса эти структуры данных оператору, обрабатывающему таблицу фактов, такому, как сканирование таблицы. Этот оператор использует информацию о строках таблицы измерения, чтобы исключить строки таблицы фактов, которые не соответствуют условиям соединения против измерений. SQL Server убирает эти строки таблицы фактов очень рано в процессе обработки запроса – после получения строки из таблицы фактов. Это позволяет экономить время работы ЦП и, возможно, сократить ввод/вывод с диска, потому что убранные строки не нужно обрабатывать в дальнейших операторах плана запроса. SQL Server использует растровое представление, чтобы эффективно реализовать структуры данных информации об уменьшении соединения во время выполнения запроса. Конвейер оптимизации запросов типа «звезда»Процесс оптимизации использует стандартную эвристику для оптимизации запроса, чтобы создать исходный набор вариантов плана выполнения запроса. Затем вызываются специальные расширения, чтобы создать дополнительные варианты плана запроса. В случае хранения данных расширение определяет схемы типа «звезда», схемы типа «снежинка», последовательности запроса «звезда» и оценивает избирательность запроса относительно таблицы фактов. Если схема и форма запроса соответствуют последовательностям, SQL Server автоматически добавляет последующие планы запроса в пространство планов, которое затем анализируется оптимизацией по стоимости, чтобы выбрать для выполнения лучший план запроса. Во время выполнения запроса, SQL Server следит за фактической избирательностью уменьшения соединения при выполнении. Если избирательность меняется, SQL Server динамически преобразует структуры данных информации об уменьшении соединения так, чтобы самая селективная применялась певой. Эвристика соединения типа «звезда»Многие физические модели хранилищ данных используют схему «звезда», но не полностью указывают отношения между таблицами измерения и фактов, как, например, с упомянутыми выше ограничениями внешнего ключа. Если ограничения внешнего ключа не заданы явно, SQL Server должен определять последовательности запросов в схеме «звезда» с помощью эвристики. Для этого применяется следующая эвристика.
Заметьте, что это правила эвристики. В действительности ситуаций, в которых эвристика перепутает таблицу фактов с таблицей измерений, немного. Это влияет на выбор плана, но не изменяет правильности выбранного плана. Двоичные соединения, вовлеченные в запрос типа «звезда», затем сортируются по убыванию избирательности. Избирательность соединения в этом контексте определяется как отношение мощности ввода таблицы фактов и итоговой мощности соединения, то есть избирательность соединения означает, насколько определенное измерение уменьшает мощность таблицы фактов. В общем случае следует рассматривать соединения с большей избирательностью первыми. Процессор запроса SQL Server автоматически применяет оптимизацию к запросам, соответствующим схеме "звезда" и упомянутым выше условиям, когда получаемые планы запроса оцениваются как выгодные. Поэтому нет необходимости изменять свое приложение, чтобы воспользоваться этим способом увеличения производительности. Заметьте, что некоторые из оптимизаций запроса типа «звезда», такие, как уменьшение соединения, доступны только в версии сервера SQL Server Enterprise Edition. Результаты исследования производительности соединения типа «звезда»В рамках проекта по оптимизации соединения типа «звезда» в SQL Server 2008, мы выполнили несколько исследований быстродействия, основываясь на экспериментальных и реальных клиентских рабочих нагрузках. Стоит посмотреть на результаты трех из этих нагрузок. Хранилище данных по организации продаж копрорации Майкрософт Эта рабочая нагрузка прослеживает быстродействие хранилища данных, использующегося для поддержки принятия решений в отделе организации продаж корпорации Майкрософт. Мы взяли фрагмент базы данных размером около 750 ГБ (включая индексы). Запросы это рабочей нагрузки сложны для обработки, так как многие имеют более 10 соединений. Розничная торговля Эта серия экспериментов основана на хранилище данных клиента, занятого в розничной торговле (обычный магазин и работа в Интернете). Особенности клиента – многомерная схема типа «снежинка» и обычные запросы типа "звезда". Для заполнения фрагмента хранилища мы использовали в наших экспериментах около 100 ГБ необработанных данных. Рабочая нагрузка поддержки решения Эта серия экспериментов исследует производительность рабочей нагрузки поддержки решения в многомерной базе данных размером 100 ГБ. На рис. 4 показаны результаты этих трех нагрузок. На рисунке изображен график времени ответа на запрос для всех запросов рабочей нагрузки. Эта мера – хороший показатель того, какой должна быть производительность запроса при выполнении произвольных запросов из рабочей нагрузки. Столбцы на рисунке сравнивают базовую производительность (1.0) без использования оптимизации запроса типа «звезда» с производительностью, оптимизированной для такого запроса. Все опыты были выполнены на SQL Server 2008.
Рис 4 Улучшение производительности за счет оптимизации соединения типа "звезда" Как видно на рисунке, все рабочие нагрузки значительно улучшились, от 12 до 30 процентов. Конкретные числа могут отличаться, но мы прогнозируем улучшение рабочих нагрузок поддержки решения относительно SQL Server Engine на 15-20 процентов за счет расширения оптимизаций запросов типа «звезда», которое включено в SQL Server 2008. Параллелизм секционированных таблицЧтобы ускорить обработку запросов в больших хранилищах данных, администраторы часто секционируют большие таблицы фактов по дате. Данные разделяются на группы файлов, уменьшая объем данных, который нужно просмотреть при обработке строк в определенном диапазоне; также это позволяет одновременно использовать производительность подлежащей дисковой системы, когда группы фалов расположены на многих физических дисках. В SQL Server 2005 была добавлена возможность секционировать большие соотношения на меньшие логические фрагменты, чтобы улучшить управление и администрирование больших таблиц. Это также успешно применялось для улучшения обработки запросов, особенно в больших приложениях поддержки решений. К сожалению, некоторые клиенты, использующие SQL Server 2005, столкнулись с проблемами производительности, особенно при работе на многопроцессорных компьютерах с параллельной совместно используемой памятью. При обработке параллельных запросов на секционированных таблицах в SQL Server 2005, может возникать ситуация, при которой только часть доступных потоков используется для выполнения запросов. Возьмем 64-разрядный комьютер, где запросы могут использовать до 64 потоков одновременно. Запрос при этом затрагивает две секции. В SQL Server 2005 он получит только 2 из 64 потоков, используя, таким образом, только 2/64 (3.1 процента) мощности ЦП компьютера. Для некоторых запросов сообщалось о десятикратном ухудшении производительности при секционировании по сравнению с выполнением того же запроса на том же компьютере на несекционированной версии той же таблицы фактов. Следует отметить, что SQL Server 2005 был оптимизирован для работы с запросами, затрагивающими одну секцию. В этом случае процессор запросов передаст все доступные потоки для выполнения сканирования. Эта особая оптимизация привела к значительному увеличению производительности односекционных запросов на многоядерных компьютерах, поэтому клиенты, естесственно, ожидали того же от запросов, затрагивающих несколько секций. Новая функция в SQL Server 2008, параллелизм секционированных таблиц (PTP), улучшает производительность запросов в случае секционирования, лучше используя вычислительные мощности имеющегося оборудования, независимо от того, сколько секций затрагивает запрос, или каков относительный размер отдельных секций. В типичном случае хранилища данных с секционированной таблицей фактов, пользователи смогут заметить значительное улучшение запросов, выполняющихся параллельно, особенно если количество доступных ядер процессора больше числа секций, затрагиваемых запросом. И эта новая функция работает сразу, без дополнительной настройки или изменений. Пусть у нас есть таблица фактов, представляющая данные продаж, разделенные по дате продажи на четыре секции. Представить себе это поможет диаграмма на рис. 5. Заметьте, что вместо одного кластеризованного индекса для всего диапазона данных, как в случе без секционирования, обычно есть кластеризованный индекс в столбце данных для каждой секции таблицы фактов. Предположим, что запрос Q суммирует продажи за последние семь дней. Так как новые данные о продажах постоянно добавляются в таблицу фактов через последнюю секцию (обозначенную как P4), запрос будет затрагивать различные секции, в зависимости от того, когда он выполняется. Это показано в первом ряду диаграммы, где запрос Q1 затрагивает только одну секцию, а запрос Q2 -- две, так как соответствующие данные во время выполнения находятся в секциях P3 и P4.
Рис 5 Новыя функция PTP в работе Теперь предположим, что доступно восемь потоков. Выполнение Q1 и Q2 под SQL Server 2005 может привести к неожиданному поведению. SQL Server 2005 устроен так, что оптимизатор знает во время компиляции, что запросом будет затронута только одна секция, что секция будет считаться одной несекционированной таблицей и что будет создан план, получающий доступ к таблице через все имеющиеся потоки. В результате для Q1, затрагивающего одну секцию (P3), возникнет план, обрабатывающийся восемью потоками (не показано на рисунке). В случае Q2, который затрагивает две секции, исполнитель передает каждой секции по одному потоку, даже если оборудование имеет дополнительные свободные потоки. Поэтому Q2 будет использовать только малую часть мощности ЦП и наверняка будет выполняться значительно медленнее, чем Q1. При выполнении Q1 и Q2 под SQL Server 2008 доступное оборудование будет использоваться полнее, что обеспечит лучшую производительность и предсказуемое поведение. В случае Q1, исполнитель снова передает все восемь доступных потоков обработке данных в P2 (не показано на рисунке). Q2, тем временем, вызовет параллельный план, в котором исполнитель передаст все доступные потоки и P3 и P4 циклическим способом, эффект чего можно видеть в нижнем ряду диаграммы, где обе секции получают по четыре потока. ЦП занять полностью, а производительность Q1 и Q2 сравнима. Такое циклическое распределение потоков позволяет тем быстрее выполнять запросы, чем больше доступно ядер процессора, по сравнению с числом секций, затрагиваемых запросом. К сожалению, не во всех случаях распределение потоков по секциям так просто, как в этом примере. Выигрыш в производительности SQL Server 2008 по сравнению с SQL Server 2005 для случая многоядерного компьютера проиллюстрирован еще на рис. 6. Этот характерный график демонстрирует производительность сканирования для секционированных таблиц. Для этого теста, который проводился в системе с 64 ядрами и 256 ГБ оперативной памяти, мы разделили одну таблицу размером 121 ГБ на 11 секций по 11 ГБ. Для набора тестов на этом рисунке мы организовали файлы в структуру сортирующего дерева, как с холодным, так и с горячим запуском. Все запросы производят простые сканирования данных.
Рис 6 Производительность сканирования для SQL Server при включении новой функции PTP По оси ординат отложено время (в секундах), а по оси абсцисс – степень параллелизма (DOP), которая аналогична количеству потоков, отданных запросу. Можно видеть, что и при горячем, и при холодном запусках время отклика уменьшается до тех пор, пока DOP не достигнет 22. В этот момент для случая холодного запуска насыщается система ввода-вывода. Это связано с тем, что запрос в этом примере зависим от ввода-вывода. Для более ЦП-ориентированных нагрузок это ограничение может не наступить или наступить при более высокой DOP. Кривая, представляющая случай горячего запуска, тем не менее, продолжает показывать уменьшение времени отклика с увеличением уровня DOP. В SQL Server 2005 обе кривые начали бы падать примерно на DOP 11, потому что при работе с несколькими секциями количество потоков на секцию было бы ограничено 1. Важно отметить, что на практике уменьшение времени отклика при увеличении числа DOP не бывает линейным. Ожидаемое поведение скорее напоминает пошаговое движение, потому что запрос ждет самой медленной части. Например, если добавить еще один поток к сканированию, общее время не уменьшится, если только не добавиь по потоку к остальным сканированиям, чтобы они тоже могли ускориться. Мы провели дополнительные эксперименты, чтобы проверить поведение PTP для других конфигураций оборудования и файлов. При этом мы отметили сходное поведение – увеличение пропускной способности при уровне DOP большем, чем один поток на секцию. Наконец, что немаловажно, новая функция PTP в SQL Server 2008 улучшает удобочитаемость планов запросов и позволяет лучше понять выполнение некоторых рабочих нагрузок. Например, благодаря функции PTP, улучшилось то, как представлены в Showplan XML параллельные и серийные планы, также усовершенствовано предоставление информации о секционировании для планов при компиляции и планов при выполнении. Сжатие данныхПо мере того, как бизнес-аналитика становится популярной, предприятия добавляют все больше данных для анализа в свои хранилища. Результат – экспоненциальный рост объема управляемых данных. В 1995 первое исследование размера баз данных корпорацией Winter Corporation позволило выяснить, что крупнейшая система в мире содежит терабайт данных. Спустя десять лет крупнейшая база данных была уже в 100 раз больше. Впечатляет то, что размер хранилищ данных утраивается каждые два года. Это ставит новые вопросы об управлении такими большими объемами данных и обеспечении приемлимогой скорости выполнения запросов к хранилищам данных. Эти запросы обычно сложные, включающие много соединений и агрегатов, им нужен доступ к большим объемам данных. И многие запросы в рабочей нагрузке зависят от ввода-вывода. Эту проблему помогает решить собственное сжатие данных. В SQL Server 2005 SP2 был включен новый формат хранения переменной длины под названием vardecimal, для десятичных и числовых данных. Этот новый формат хранения может значительно уменьшить размер баз данных. Выигрыш в объеме может, в свою очередь, двумя способами улучшить производительность запросов, зависимых от ввода-вывода. Во-первых, нужно считывать меньше страниц, а во-вторых, так как данные хранятся в буферном пуле сжатыми, увеличивается ожидаемое время жизни страницы (иначе говоря, увеличивается вероятность, что нужная страница окажется в буфере). Конечно, выгода в объеме от сжатия данных приводит к нагрузке на ЦП в процессе сжатия и распаковки данных. SQL Server 2008 использует формат хранения vardecimal, обеспечивая два вида сжатия: сжатие ROW и PAGE. Сжатие ROW расширяет формат хранения vardecimal за счет хранения всех типов данных фиксированной длины в формате хранения переменной длины. Некоторые примеры типов данных фиксированной длины -- integer, char и свободные типы данных. Несмотря на то, что SQL Server хранит эти типы данных в формате переменной длины, их семантика не меняется (с точки зрения приложения, тип данных продолжает быть фиксированной длины). Это значит, что можно воспользоваться преимуществами сжатия данных, не изменяя свои приложения. Сжатие PAGE уменьшает изыбточность данных в столбцах в одной или более строке на данной странице. Оно использует собственную реализацию алгоритма LZ78 (Лемпеля-Зива), сохраняя избыточные данные единожды на странице, ссылаясь затем на них из многих столбцов. Заметьте, что если вы используете сжатие PAGE, сжатие ROW тоже используется. Сжатие ROW и PAGE можно включить для таблицы, индекса или одной и более секций секционированных таблиц и индексов. Это дает полную гибкость выбора таблиц, индексов и секций для сжатия, позволяя найти баланс между выигрышем в объеме и нагрузкой на ЦП. На рис. 7 это проиллюстрировано с помощью таблицы продаж, секционированной различными способами с выровненными индексами.
Рис 7 Секционированная таблица с различными настройками сжатия Каждая секция представляет квартал, последний квартал – Oct-Dec. Предположим, что первые две секции используются редко, третья – средне, а последняя – наиболее активно. В этом случае можно включить сжатие PAGE для первых двух секций, чтобы получит максимальную экономию места, мнимально затронув производительность рабочей нагрузки, сжатие ROW для третьей секции и не сжимать последнюю. Сжатие можно включить в автономном или оперативном режиме с помощью выражений Alter Table или Alter Index языка DDL. SQL Server также позволяет оценить экономию места. Получаемая экономия места будет зависеть от распределения данных и схемы сжимаемого объекта. На основании результатов тестов баз данных многих клиентов, можно предположить, что большинство клиентов смогут уменьшить размер базы данных на 50-64 процентов и зачительно увеличить производительность запросов, зависимых от ввода-вывода. Однако, оценка производительности запросов, свзанных с ЦП, посложнее и зависит от сложности запроса. В SQL Server нагрузка от распаковки возникает только при доступе к индексу или таблицам. Если относительная нагрузка на ЦП операторов сканирования невелика по сравнению с общей нагрузкой запроса на ЦП, как обычно бывает с хранилищами данных, влияние на использование ЦП не должно превышать 20-30 процентов. Индексированные представления, выровненные по секциямВ SQL Server 2008 индексированные представления, выровенные по секциям, позволяют более эффективно создавать и управлять общими агрегатами в реляционном хранилище данных, а также использовать их в тех сценариях, в которых раньше это было неэффективно. Это повышает производительность запроса. В типичном случае, есть таблица фактов, секционированная по дате. Индексированные представления (или общие агрегаты) определяются на этой таблице, чтобы ускорить запросы. При переключении на новую секцию таблицы соответствующие секции индексированных представлений, выровненных по секциям, определенные на секционированной таблице, тоже переключаются, причем автоматически. Это значительно лучше, чем в SQL Server 2005, где нужно было удалить все индексированные представления, определенные на секционированной таблице, прежде чем использовать операцию ALTER TABLE SWITCH, чтобы подключить или отключить секцию. Функция индексированных представлений, выровненных по секциям, дает в SQL Server 2008 преимущества индексированных представлений на больших секционированных таблицах без необходимости перестраивать агрегаты на всей секционированной таблице. К этим преимуществам относятся автоматическое поддержание агрегатов и сопоставление индексированного представления. Укрупнение блокировок на уровне секцииSQL Server поддерживает секционирование по диапазону, позволяющее секционировать данные для простоты управления или группировать данные на основании схемы использования. Так, например, данные продаж можно секционировать по месяцам или кварталам. Можно сопоставить секцию с ее файловой группой, а файловую группу, в свою очередь, с группой файлов. Это дает два преимущества. Во-первых, можно создавать резервные копии и восстанавливать секцию как независимый элемент. Во-вторых, можно сопоставить файловую группу с быстрой или медленной подсистемой ввода-вывода, в зависимости от схемы использования или загрузки запросами. Интересный момент – схема доступа к данным. Запросы и операции DML могут нуждаться в доступе или манипуляциях только с частью секций. Поэтому если вы, например, анализируете данные продаж за 2004 год, вам требуется доступ только к соответствующим секциям; в идеальном варианте, запросы, обращающиеся к данным в других секциях, не должны оказывать на это никакого влияния (не считая ресурсов системы). В SQL Server 2005 одновременный доступ к различным секциям может привести к блокировке таблицы, которая может затруднить доступ к другим секциям. Чтобы уменьшить эти помехи, в SQL Server 2008 включен на уровне таблиц параметр, позволяющий контролировать укрупнение блокировок на уровне секции или таблицы. По умолчанию укрупнение блокировок включено на уровне таблиц, как и в SQL Server 2005. Однако, политику укрупнения блокировок для таблицы можно изменить. Например, можно установить такое укрупнение блокировок: Alter table <mytable> set (LOCK_ESCALATION = AUTO) Эта команда предписывает SQL Server выбрать подходящую для схемы таблицы гранулярность укрупнения блокировок. Если таблица не секционирована, укрупнение блокировок будет на уровне TABLE (таблицы). Если она секционирована, то гранулярность укрупнения блокировок будет на уровне секции. Этот параметр также используется в SQL Server как способ уменьшить вероятность гранулярности блокировки на уровне таблицы. ЗаключениеМы представили короткий обзор новых функций SQL Server 2008, которые помогут вам достичь большей производительности запросов поддержки решений в реляционных хранилищах данных. Но не забывайте, что, хотя высокая скорость отклика на запросы поддержки решений очень важна, есть и другие принципиальные условия, не описанные в этой статье. К некоторым дополнительным функциям, имеющим отношение к реляционному хранению данных, относятся:
Мы советуем ознакомиться с более полной информацией о всех этих замечательных функциях на странице SQL Server в Интернете, по адресу microsoft.com/sql.
Теги:
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|