| Новые программы oszone.net |
Наконец-то он вышел! Прямо скажем, заждались. AMD успела представить флагманский видеоадаптер серии Southern Islands еще в декабре прошлого года, а теперь уже выпустила полную линейку Radeon HD 7000. И каждый раз, тестируя очередную новинку от AMD, мы задавали вопрос: когда же выйдет Kepler? Но предполагаемая дата релиза неоднократно переносилась. Сначала NVIDIA официально заявила, что Kepler не выйдет в 2011 году, потом пропали надежды на выход в январе. И вот наконец… За все это время Kepler оброс самыми невероятными слухами. Каждый новый «слив» внутренних презентаций NVIDIA или диаграммы непонятного происхождения усиливали путаницу и ажиотаж. Позволим себе напомнить основные этапы интриги, чтобы потом все торжественно опровергнуть. Для начала вот этот нашумевший слайд. Судя по тому, что здесь написано, в начале 2012 года мы должны были увидеть бюджетный GPU GK107 со 128-битной шиной памяти и PCI-E 2.0, затем более мощный чип GK106 (шина памяти 256 бит, PCI-E 3.0) и GK104, похожий на GF110 своей 384-битной шиной. Ну а в конце 2012 — начале 2013 года нас якобы ждет двухпроцессорная карта на базе GK104 и однопроцессорный монстр GK112 с 512-битной шиной памяти. 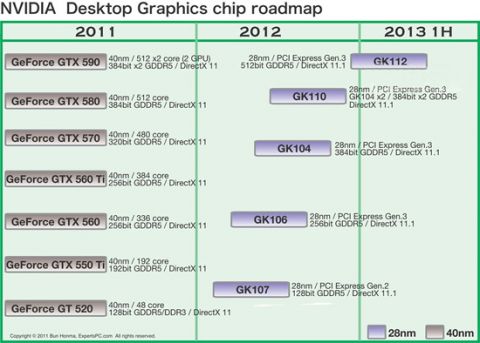 В следующих новостях монстр засветился под именем GK100, и стали известны подробности о его архитектуре: 1024 ядра CUDA, 128 текстурных модулей и 64 ROP. GK104 приписали 640 либо 768 ядер, 80 или 90 TMU и 48 ROP. Затем появился весьма сомнительный слайд, в котором уже фигурирует не то что GeForce GTX 600-серии, а GTX 780, вдвое превосходящий действующий флагман NVIDIA на тот момент — GTX 580. Глядя на такие результаты, легко провести параллели между GTX 780 и тем самым процессором GK100 с 512-битной шиной памяти. Слайд зародил сомнения: если информация соответствует реальным планам NVIDIA, релиз GK100 будет далеко не скоро. 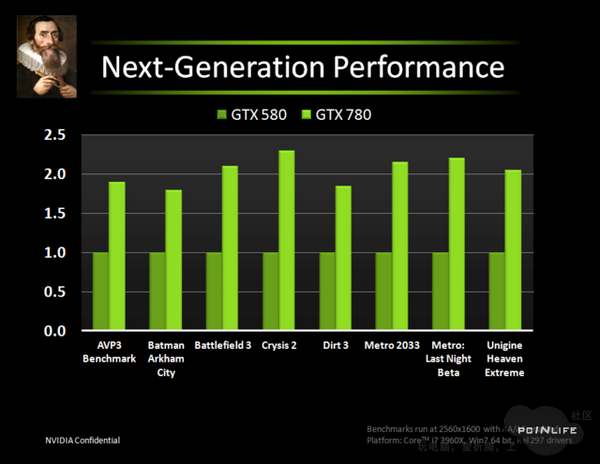 Увеличить Затем чудесным образом возникли полные (но весьма сомнительные) данные обо всей линейке GTX 600, из которых следует, что в GK100 войдет аж 6,4 млрд. транзисторов. Но акцент уже сместился в направлении младших чипов. Всплыли подробные спецификации GK104, и некоторые источники уже утверждали, что именно этот кристалл ляжет в основу флагманской модели GeForce GTX 680. Теперь мнения об архитектуре GK104 объединились: 1536 ядер CUDA, 128 текстурных блоков, 32 ROP и 256-битная шина памяти. Похоже, что в NVIDIA до последнего момента сомневались, под каким модельным номером этот адаптер поступит в продажу. Может быть, все-таки GTX 670 Ti? Но, вы знаете, так оно в конце концов и вышло. Забудьте о монстре с 512-битной шиной памяти. GeForce GTX 680 основан на GPU GK104. Архитектура GK104 Спецификации Последние «сливы» оказались чистой правдой. GK104 действительно содержит 1536 ядер CUDA, что втрое больше, чем у GF110 (GeForce GTX 580), 128 текстурных блоков (больше в два раза) и 32 ROP (а вот это шаг назад, у GF110 их 48). Ширина шины памяти — 256 бит, но работает она на эффективной частоте 6008 МГц. «Шея стала тоньше, но зато длинней». Объем памяти — 2 Гбайт. Поддерживается интерфейс PCI-E 3.0 GPU имеет базовую тактовую частоту 1006 МГц (что значит «базовая частота», мы объясним ниже), а частота ядер CUDA больше не удвоена по отношению к остальным компонентам. Это сделано для экономии электроэнергии. И действительно, карта уложилась в TDP 195 Вт. Довольно скромный показатель для флагманского продукта (у GeForce GTX 580 — 244 Вт, а у Radeon HD 7970 — 250 Вт), особенно в свете предыдущих «достижений» NVIDIA в этой области. GPU производится по техпроцессу 28 нм и включает 3,54 млрд транзисторов — «всего лишь» на 0,54 млрд больше, чем в GF110. Для сравнения: в чипе Tahiti (Radeon HD 7970) 4,38 млрд транзисторов. Рекомендованная розничная цена — $499, в России — 17 999 р. Для сравнения: рекомендованная цена Radeon HD 7970 на момент релиза — $549. 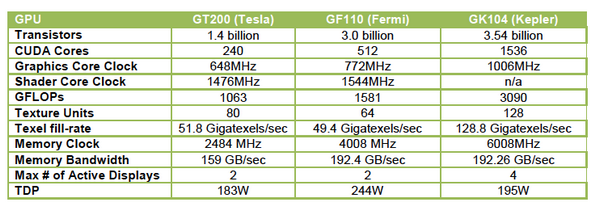 Увеличить Вот что вкратце можно сказать о GeForce GTX 680. Нетерпеливые читатели уже могут перейти к разделу «Тестирование», а гиков приглашаем разделить с нами особое удовольствие — подробный разбор архитектуры Kepler. Общая схема Как и процессоры Fermi, Kepler имеет легко масштабируемый модульный дизайн. Все вычислительные компоненты распределены между четырьмя «графическими кластерами» (Graphics Processing Cluster, GPC). Вне кластеров находится только общий кеш L2, контроллеры памяти, ROP (на схеме — голубые блоки рядом с кешем) и блок GigaThread Engine, распределяющий нагрузку между GPC. 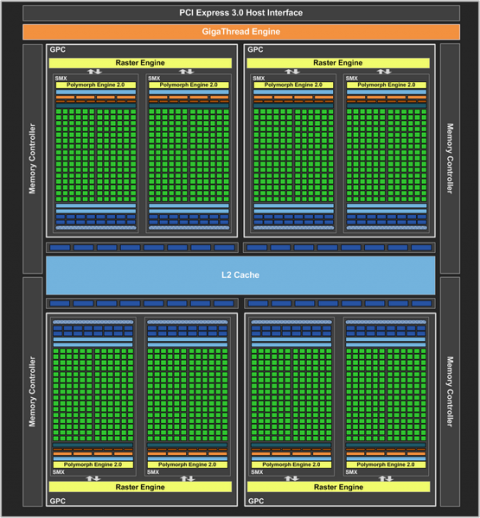 Блок-схема GK104 (кликабельно) В GK104 только четыре контроллера памяти по сравнению с шестью у GF110. GPC, как и у GF110, те же четыре штуки. Каждый GPC состоит из блока растеризации (Raster Engine) и потокового мультипроцессора (SMX). Raster Engine представляет собой конвейер из трех стадий, на которых происходит вычисление граней геометрических примитивов, проекция пикселей на поверхности и отсечение невидимых пикселей соответственно. Подробно о каких-либо изменениях в Raster Engine NVIDIA не сообщает, но, судя по официальному слайду, теперь их производительность один к одному согласуется с пропускной способностью ROP. Ну да, если каждый Raster Engine за такт обрабатывает 8 пикселов, как в Fermi, то четыре «движка» обрабатывают 32 пиксела, что соответствует 32 ROP.  Увеличить Потоковые мультипроцессоры Потоковые мультипроцессоры были сильно переработаны. Неспроста к их аббревиатуре для большей крутости прибавили букву X (SMX). Для начала — общая информация о том, как работает мультипроцессор в архитектуре Kepler. Как и в Fermi, мультипроцессор объединяет основные вычислительные мощности GPU: текстурные блоки, геометрический движок PolyMorph Engine и массив ядер CUDA. Каждое ядро CUDA представляет собой полностью конвейеризированный процессор с одним целочисленным ALU и блоком вычислений с плавающей точкой. С помощью сотен таких ядер GPU выполняет шейдерные программы и вычисления для неграфических приложений с API OpenCL, DirectCompute, PhysX и, собственно, CUDA API. Внутри SM ядра CUDA используются совместно с другими вычислительными компонентами: блоками Load/Store (LD/ST), текстурными блоками, блоками интерполяции (нет на диаграмме NVIDIA), блоками вычисления специальных функций (Special Function Units, SFU) — тригонометрических, например. Все эти компоненты получают инструкции для выполнения от одних и тех же диспетчеров. 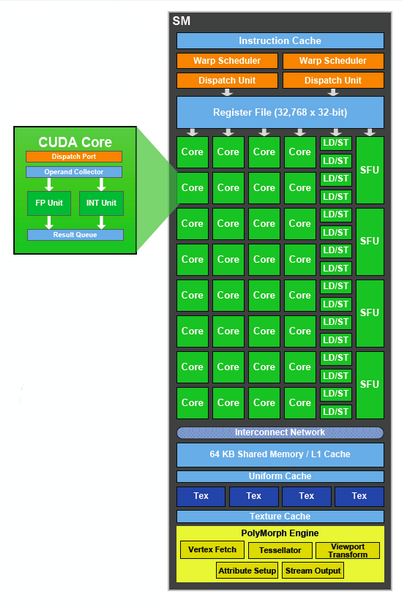 GF100/110 — потоковый мультипроцессор и ядро CUDA Весь пафос вычислений на GPU, будь то шейдеры или массированные неграфические расчеты, в следующем: программа порождает множество потоков инструкций (threads), и выполнение можно организовать таким образом, что в один момент времени большая часть потоков выполняет одну и ту же операцию, только с разными данными. Рабочая нагрузка для ядер CUDA внутри мультипроцессора поступает в виде пучков из 32 потоков (warp). В каждом ряду warp могут быть только одни и те же инструкции. Если это невозможно, то места в ряду пустуют. Каждый такт диспетчер выбирает подходящий warp из 32 активных на мультипроцессоре, берет 32 инструкции (по одной «крайней» инструкции из каждого потока) и отправляет их на исполнение группе из 16 ядер CUDA (в то же время вместо 16 ядер CUDA диспетчер может загрузить все блоки LD/ST, либо все блоки интерполяции, либо все текстурные блоки). Стоп, как же 16 ядер могут выполнить за один такт 32 инструкции? Вот тут вступают в дело двойные частоты Fermi. Ядра CUDA, блоки LD/ST и SFU работают в два раза быстрее и за один такт диспетчера срабатывают два раза. 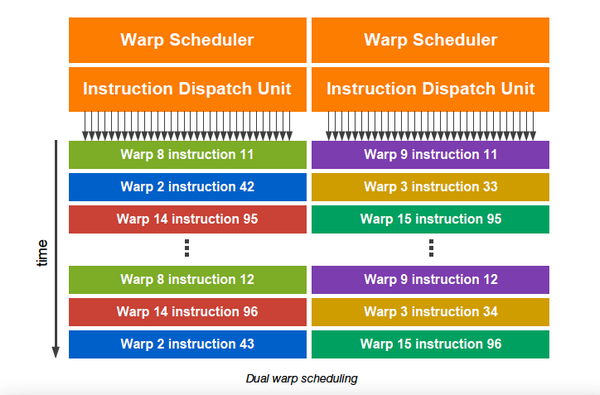 Увеличить Какие же изменения принес Kepler? Во-первых, все блоки SMX теперь работают на одной частоте, зато их стало больше. Конфигурация мультипроцессора GF100/110: 32 ядра CUDA, 16 блоков интерполяции, 16 блоков LD/ST, 4 SFU, 4 текстурных блока. GK104: 192 ядра CUDA и 16 текстурников, 32 SFU и 32 LD/ST. Важное дополнение: в состав SMX входит еще один блок из восьми ядер CUDA, который скрыт на диаграмме. Это специальные ядра, способные выполнять вычисления двойной точности (FP64). 32 инструкций из одного warp выполняются им за четыре такта, но каждая инструкция – на полной скорости. В целом GK104 выполняет расчеты FP64 со скоростью 1/24 от FP32. (Прим.: в мультипроцессорах чипа GF114 один из трех блоков по 16 ядер CUDA тоже мог выполнять операции двойной точности, но только на скорости 1/4.) Между тем архитектура GCN от AMD на хардверном уровне поддержвает расчеты FP64 со скоростью 1/2. 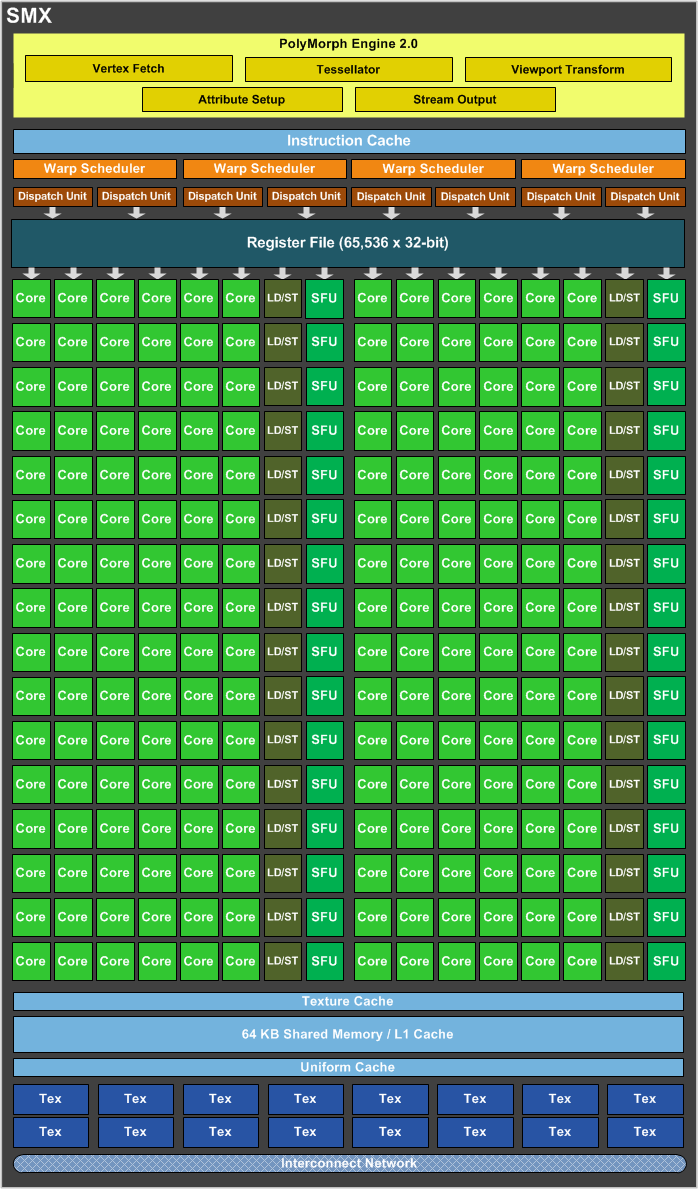 Потоковый мультипроцессор GK104 (кликабельно) Потоковый мультипроцессор GK104 (кликабельно) 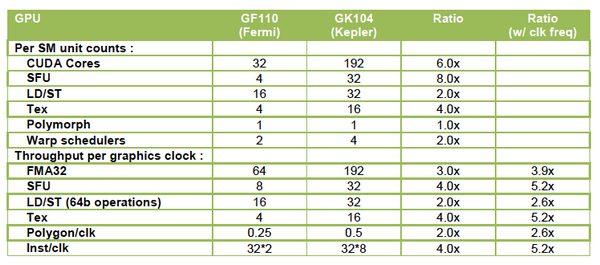 Увеличить Конфигурация потоковых мультипроцессоров в GK104 и GF100/110 Во-вторых, планировщиков тоже стало в два раза больше. И с каждым планировщиком теперь связано два диспетчера. Они могут одновременно отправлять на исполнение сразу два «ряда» инструкций из одного warp, если один из них не зависит от выполнения другого. Таким образом, потоковый мультипроцессор приобретает функцию внеочередного исполнения, что роднит его с CPU. (Прим.: опять-таки двойные диспетчеры NVIDIA уже применяла в GF104 и последующих GPU среднего и начального уровня, только в GF110 они так и не появились.) В-третьих, логика планировщика подверглась упрощению. В Fermi планировщик определял зависимости операций в шейдерном коде и переупорядочивал выполнение различных warp. Теперь задача разрешения зависимостей возложена на компилятор. В самой инструкции сообщается, на каком этапе в будущем она может быть отправлена на исполнение, и пока этот момент не настал, планировщик выбирает для исполнения другие warp. Мотивация NVIDIA понятна: сложные планировщики с разрешением зависимостей обременяют энергетический бюджет. Но эффективность неграфических вычислений без них неизбежно пострадает. Неспроста AMD перешла к динамическому планированию в архитектуре Graphics Core Next (вся смена архитектуры, по сути, была закручена вокруг этого). А вот NVIDIA, напротив, жертвует производительностью в пользу энергетической эффективности. Впрочем, разработчики наверняка взвесили все за и против. Возможно, в неграфических расчетах этот шаг повысил производительность на ватт. А может, это свойство не самого продвинутого потребительского GPU и в более мощных версиях Kepler вернется динамическое планирование. 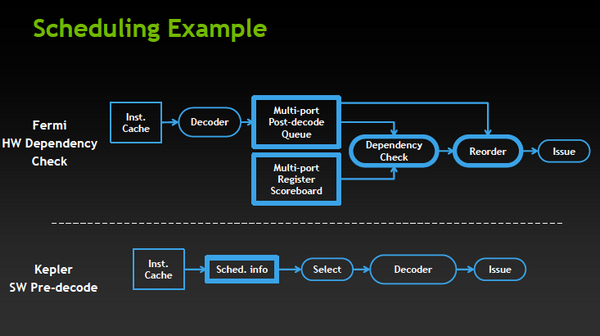 Увеличить Обработка геометрии В архитектуре Fermi нет отдельного геометрического блока, как в Graphics Core Next от AMD. Вместо этого в каждом потоковом мультипроцессоре есть собственный PolyMorph Engine, и они соединены специальным интерфейсом. Именно благодаря геометрической мощи адаптеры GeForce доминировали в задачах с тесселяцией вплоть до выхода карт Radeon серии HD 7000, которые серьезно проапгрейдили по этой части. В GK104, обратите внимание, блоков PolyMorph Engine стало меньше по сравнению с GF110, так как меньше потоковых мультипроцессоров. Но NVIDIA уверяет: PolyMorph Engine версии 2.0 стал почти вдвое более эффективным, что с лихвой компенсирует сокращение.  Увеличить По данным внутреннего тестирования, GeForce GTX 680 заметно превосходит GTX 580 при высоком Expansion Factor (глубокая тесселяция). На том же графике приведен Radeon HD 7970, но его производительность почему-то совсем не колеблется, что вызывает большие сомнения в результатах. 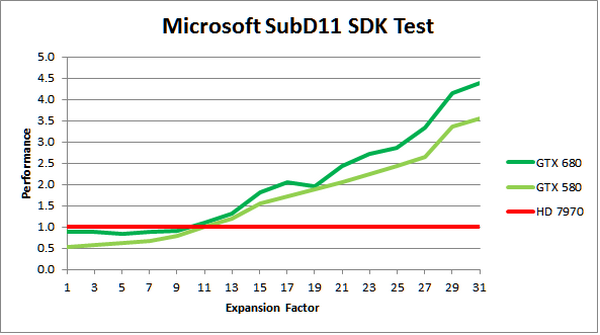 Увеличить Кеш-память Как и у GF100/110, в каждом потоковом мультипроцессоре GK104 есть кеш L1 объемом 64 Кбайт. А вот общий кеш L2 уменьшился: с 768 до 512 Кбайт. Однако пропускная способность кеша увеличилась на 73%. Выросла скорость атомарных операций (чтение + запись).  Увеличить Новые функции GPU и драйвера GPU Boost Эта функция — аналог PowerTune в последних видеокартах Radeon. Фактически она представляет собой динамический разгон GPU в те моменты, когда это позволяет энергопотребление. NVIDIA показывает, что в большинстве игр карта не добирает мощности до заявленного TDP (195 Вт), а потому частоту процессора можно существенно увеличить. В спецификациях карты теперь указывается отдельно Base Clock — собственно, минимальная частота GPU в 3D-режиме и Boost Clock — средняя частота, которая достигается в распространенных приложениях (в данном случае — 1058 МГц). Для контроля мощности адаптера используется как аналоговый датчик в системе питания (довольно инерционный), так и цифровые датчики загрузки GPU и памяти (более чуткие). Дополнительно на автоматический разгон влияет температура GPU. 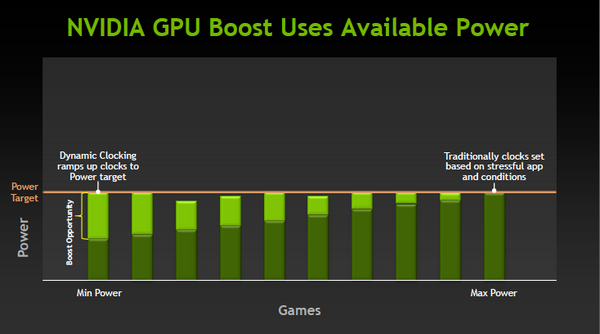 Увеличить Несмотря на общее сходство, GPU Boost в работе выглядит не так, как PowerTune от AMD. Присутствие последней фактически незаметно, и изменение частоты не регистрируется утилитами мониторинга. Частота GPU нового GeForce меняется на глазах. В наших тестах она действительно колебалась вокруг заявленного уровня 1058 МГц. И напряжение питания меняется тоже. Как теперь реализован разгон вручную — отдельная тема. Всякая прибавка к базовой частоте линейно отражается на частоте Boost Clock, и она превращается из 1058 МГц в, допустим, 1158 МГц, если не упрется в ограничение мощности. Чтобы поднять потолок Boost Clock, нужно увеличить допустимую мощность. Пока что это умеет делать только специальная версия утилиты EVGA Precision X. О результатах наших экспериментов с разгоном GTX 680 вы можете прочитать в соответствующем разделе. Adaptive VSync Зачем нам нужна вертикальная синхронизация? Чтобы устранить разрывы изображения при смене кадров, которые особенно часто возникают в случае, если FPS превышает частоту вертикальной развертки дисплея.  Увеличить Так выглядят разрывы кадра в отсутствии VSync А почему вертикальную синхронизацию так редко используют? Потому что если FPS меньше частоты развертки, VSync приводит его к половине или четверти частоты, например 30 и 15 FPS. Возникают тормоза. Чтобы устранить этот недостаток, NVIDIA предложила простое решение: если FPS больше частоты развертки, то VSync работает, а когда падает меньше, VSync отключается. Эта функция совместима и с картами GeForce предыдущего поколения. 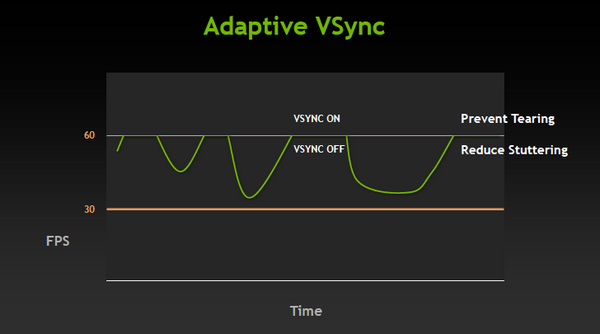 Увеличить FXAA и TXAA Многие игры прошлого года использовали новый метод полноэкранного сглаживания — FXAA. Оказалось, что для современных движков с отложенным рендерингом (Deferred Rendering) привычный метод MSAA представляет большую проблему. Его трудно реализовать, и падение производительности получается куда большим, чем у движков прямого рендеринга (Forward Rendering), распространенных во времена DirectX 8-9. FXAA фактически представляет собой фильтр пост обработки, который обнаруживает и размывает границы полигонов. Он радикально быстрее, чем MSAA, но изображение выглядит не столь резким, как при использовании MSAA или вообще без сглаживания. Мы это наглядно показали на примере Skyrim.   С выходом GeForce GTX 680 NVIDIA еще раз привлекла внимание к FXAA, продемонстрировав знаменитую демку Samaritan в реальном времени. На прошлогодней выставке GDC 2011 Samaritan со сглаживанием MSAA запускали на трех GeForce GTX 580 в режиме SLI. С FXAA достаточно и одного GTX 680, хотя производительность одиночной карты, конечно, тоже выросла. Но понятно, что FXAA — это временное решение, которое по качеству никогда не сравнится с MSAA. Поэтому NVIDIA предлагает новый метод — TXAA. Он представляет собой некую комбинацию мультисемплинга и постобработки (более глубоких подробностей у нас пока нет). В варианте TXAA 1 заявлено более качественное сглаживание краев полигонов, чем при MSAA 8x, с потерей производительности на уровне MSAA 2x. TXAA 2 обеспечивает гораздо более высокое качество, чем MSAA 8x с затратами на уровне MSAA 4x. TXAA будет предоставляться разработчикам игр в виде библиотек и будет работать на любом современном железе, не только на GeForce 600. В текущем году уже ожидаются первые игры с поддержкой TXAA.   Bindless Textures А вот еще одна функция, эксклюзивная для Kepler. В Fermi шейдерная программа могла обращаться только к 128 текстурам, указанным в специальной таблице. Теперь текстуры в памяти доступны шейдеру напрямую, более миллиона текстур одновременно. Потенциально эта функция увеличивает богатство игровых сцен, но API DirectX 11 все равно ограничивает шейдер 128 текстурами, поэтому Bindless Textures пока можно использовать только в OpenGL или непосредственно с помощью NVAPI.  Увеличить Новые видеоинтерфейсы, мультимониторные конфигурации GeForce GTX 680 в референсной конфигурации поддерживает интерфейсы DisplayPort 1.2 и HDMI 1.4a, совместимые с разрешением 3840x2160, а также два Dual-Link DVI. К одной карте теперь можно подключить сразу четыре монитора. 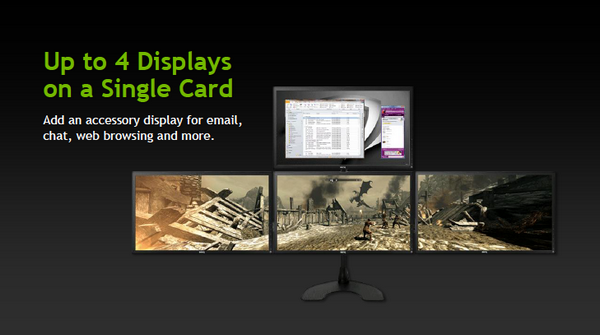 Увеличить В режиме Surround появилось несколько дополнительных функций.
Новый видеокодировщик В Kepler включен новый кодировщик стандарта H.264 — NVENC. До сей поры видео на картах NVIDIA кодировалось на ядрах CUDA, но, по утверждению производителя, NVENC работает в четыре раза быстрее, потребляя при этом значительно меньше электроэнергии. NVENC совместим с разрешениями вплоть до 4096х4096, а Full HD может кодировать на скорости в 8 раз быстрее воспроизведения. Поддерживает стереоскопическое видео. Сейчас функции NVENC доступны через специальный API, и разработчикам предоставляется SDK. Позже появится возможность одновременно с кодированием задействовать ядра CUDA для дополнительной обработки видео или использовать для кодировки совместные мощности кодировщика и ядер. Новые функции PhysX В API высокого уровня APEX (а значит — для всех видеокарт с PhysX) скоро войдут функции динамического разрушения объектов и отображения меха. Особенно интересно первое. Сейчас разрушение игровых объектов определяется заранее, но, благодаря новой функции, GPU будет создавать осколки автоматически, каждый раз по-новому.  Увеличить DirectX 11.1 NVIDIA нигде не утверждает о полной поддержке спецификации DirectX 11.1, но, на самом деле, поддерживаются все функции нового стандарта, относящиеся к 3D-рендерингу:
Не реализованы только некоторые неигровые функции:
Конструкция С виду карта не сильно отличается от GTX 580. Для охлаждения по-прежнему используется массивный кулер-турбина.
Питание подается по двум шестиконтактным разъемам (для GTX 580 требовался шестиконтактный плюс восьмиконтактный), причем расположены они один над другим — для экономии места на плате.  Увеличить Система охлаждения в общих чертах осталась такой же. Есть массивная алюминиевая рама, к которой через термопрокладки прижаты микросхемы памяти и компоненты системы питания, и есть отдельный радиатор с тепловой трубкой для GPU. Испарительная камера, судя по всему, исчезла. Ребра радиатора ближе к хвосту карты скошены, что должно облегчить прохождение воздуха через уменьшенную решетку. Турбинка сделана из звукопоглощающего материала. И действительно, даже на максимальных оборотах (точнее, на 85%: драйвер не дает выставить больше) кулера шум не настолько велик, как можно было ожидать. Radeon HD 7970 на 85% шумит гораздо сильнее.  Увеличить
 Увеличить Расположение портов на заглушке платы изменилось. Хорошо, что HDMI и DisplayPort выводятся через полноразмерные разъемы, – нет нужды в переходниках.
Плата По сложности платы GeForce GTX 680 соответствует 580-й модели. Только микросхем памяти меньше. Это чипы Hynix H5GQ2H24MFR R0C, 6 ГГц для них – штатная эффективная частота. Да, обратите внимание на посадочную площадку для еще одного разъема питания. Это следы старого дизайна с классическими «одноэтажными» разъемами? Не собиралась же NVIDIA выпустить карту с тремя коннекторами…
В системе питания по-прежнему используются шесть фаз: четыре для GPU и две для памяти. Питанием GPU управляет контроллер Richtek RT8802A на забавной дочерней плашке.  Увеличить Графический процессор впервые со времен GeForce 7800 обходится без крышки-теплораспределителя. Видимо, он достаточно компактный, чтобы не было опасности сколов при установке кулера.  Увеличить
Теги:
GeForce GTX 680.
Комментарии посетителей
Комментарии отключены. С вопросами по статьям обращайтесь в форум.
|
|










